고객 세분화와 인과 타겟팅
공개 Dunnhumby 리테일 데이터에서 NMF·K-Means 세분화를 메타러너·Causal-Forest HTE와 OPE로 검증한 최적 타겟팅 정책으로 이은 엔드투엔드 분석.
⏱️ TL;DR (30초)
- 문제 — 쿠폰 캠페인(TypeA)을 누구에게 보낼 것인가? 전체 발송은 비용만 키우고 손실을 낸다.
- 접근 — 2-Track Framework. Track 1은 “우리 고객은 누구인가”(NMF + K-Means → 7 세그먼트), Track 2는 “누구를 타겟팅해야 하는가”(CATE 추정 → 정책 학습).
- 핵심 결과 3줄
- 고가치 세그먼트(VIP Heavy, Bulk Shoppers)가 오히려 음(-)의 CATE → Ceiling/Cannibalization 효과.
- CATE > Breakeven($42.43) 규칙으로 코호트의 31.3%(152/486) 만 타겟팅하면 수익 최적.
- 관찰 데이터의 심각한 Positivity Violation(PS AUC=0.989, Overlap 17%) → 결과는 가설 생성적, A/B Test로 확증 필요.
- 임팩트 한 줄 — 전체 타겟팅(-$4,659) 대비 최적 타겟팅(+$2,426)으로 +$7,085 / +200pp ROI 개선(분석 코호트 기준, 가설 생성적 추정).
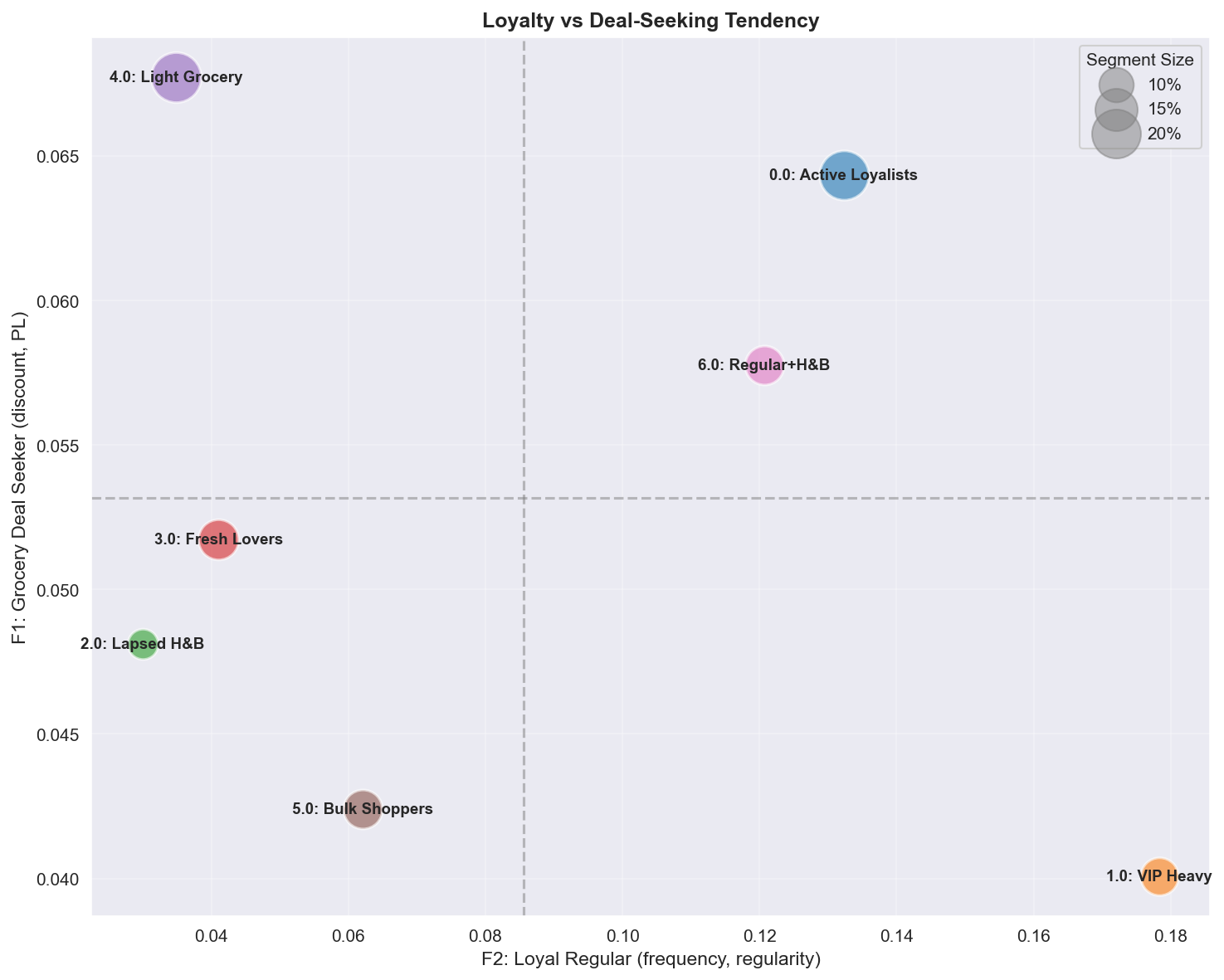 Track 1 — 충성도(F2) × 할인추구(F1) 공간의 7개 행동 세그먼트.
Track 1 — 충성도(F2) × 할인추구(F1) 공간의 7개 행동 세그먼트.
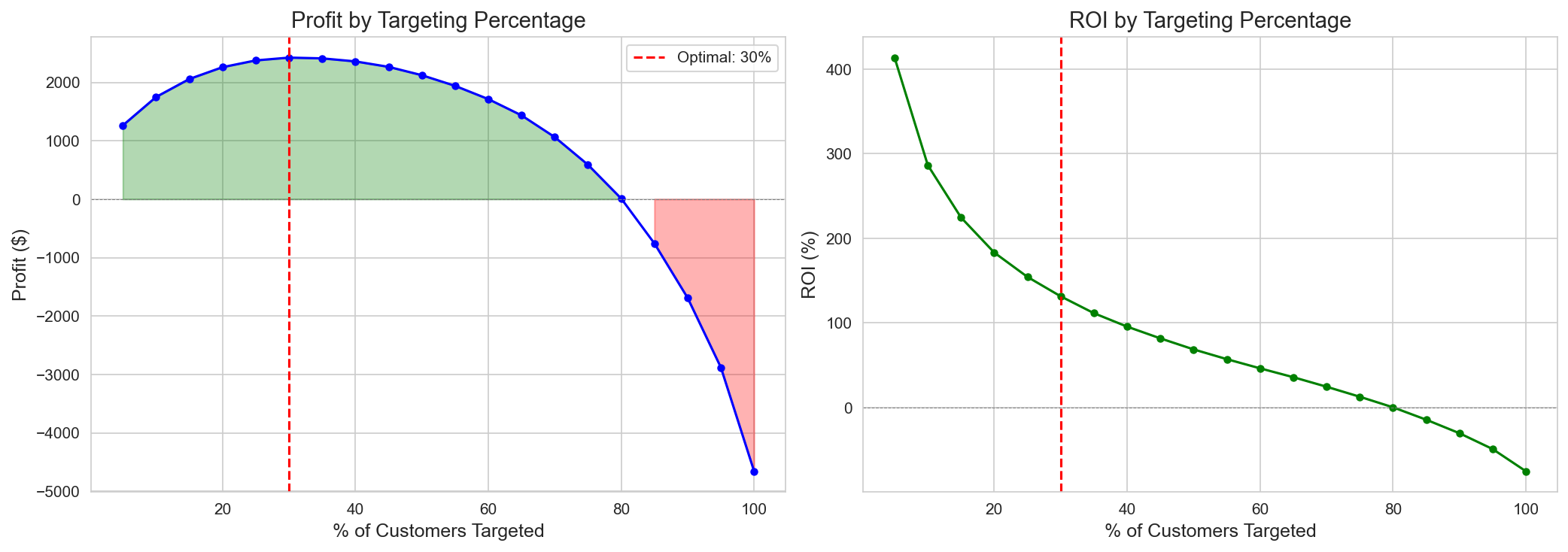 Track 2 — ROI는 약 31% 타겟팅에서 정점, 100% 타겟팅은 손실.
Track 2 — ROI는 약 31% 타겟팅에서 정점, 100% 타겟팅은 손실.
🎯 핵심 결과 한눈에
| 핵심 지표 | 값 | 비고 |
|---|---|---|
| 데이터 규모 | 2,500 가구 · ~2.6M 거래 · 102주 | Dunnhumby “The Complete Journey” |
| 세그먼트 수 | 7 (NMF k=5 → K-Means k=7) | 분산 설명 92.44%, Bootstrap ARI 0.77±0.11 |
| Breakeven CATE | $42.43 | 비용 $12.73 / 마진 0.30 |
| 최적 타겟팅 | 31.3% (152 / 486) | profit +$2,426, ROI 125% |
| 전체 타겟팅(100%) | 486명 | profit -$4,659, ROI -75% |
| 현행 관행(62.1%) | 302명 | profit -$3,402, ROI -88% |
| 개선 효과(최적 vs 전체) | +$7,085 | +200pp ROI (가설 생성적) |
| Positivity 진단 | PS AUC 0.989, Overlap 17% | 심각한 위반 → 가설 생성적 해석 |
| 1차 CATE 모델 | CausalForestDML | 저분산·타당성 기준 선택(자세히는 Track 2) |
세그먼트별 CATE — 고가치 세그먼트의 음(-)의 효과가 반직관적 핵심
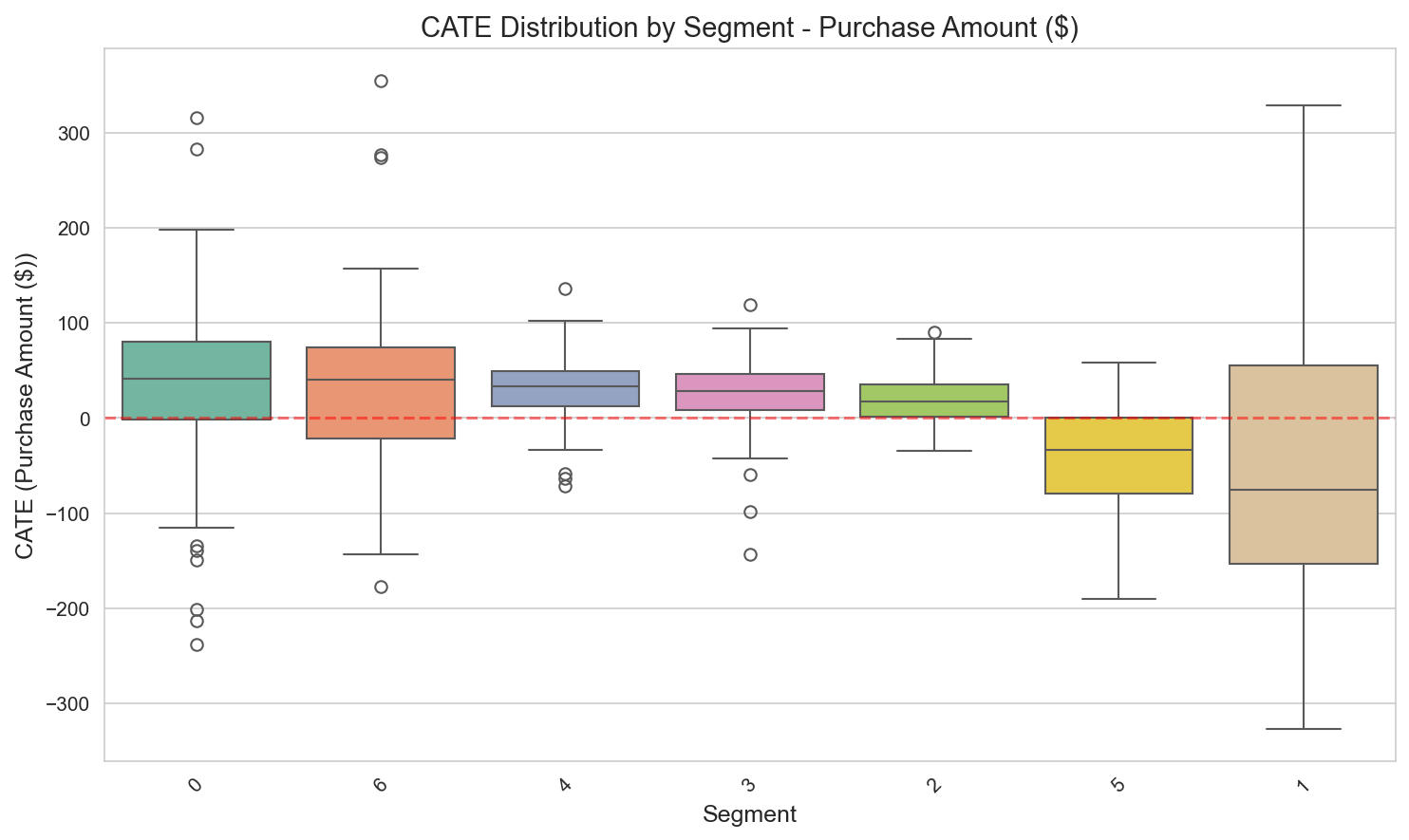 세그먼트별 CATE 분포. VIP Heavy(-$38)와 Bulk Shoppers(-$40)의 음의 효과가 명확하다 — 타겟팅 축소 신호.
세그먼트별 CATE 분포. VIP Heavy(-$38)와 Bulk Shoppers(-$40)의 음의 효과가 명확하다 — 타겟팅 축소 신호.
Motivation & Framework
본 프로젝트는 전통적 세그멘테이션의 “우리 고객은 누구인가?” 라는 질문과, 인과추론 기반의 “이 캠페인이 누구에게 얼마나 효과가 있을까?” 라는 질문을 하나의 파이프라인에서 함께 다룬다.

왜 두 Track 모두 필요한가?
| 측면 | Track 1 (Descriptive) | Track 2 (Causal) |
|---|---|---|
| 핵심 질문 | ”이 고객은 누구인가?" | "이 고객에게 캠페인이 효과적일까?” |
| 주요 사용자 | 마케팅, CRM, 전략 | Data Science, 최적화 |
| 설명 가능성 | ”Premium Fresh Lover 세그먼트" | "이 고객의 CATE = +$34” |
| 조직 요구사항 | 고객 이해 기반 마케팅 역량 | Causal thinking + 개인화 타겟팅 실행 체계 |
Key Insights: 반직관적 발견
고가치 고객의 음(-)의 Treatment Effect
아래 N은 Track 2 분석 코호트(486명) 기준이며, Track 1의 전체 세그먼트 규모(509·299·…)와는 다른 수치다. CATE는 가설 생성적 추정치다.
| 세그먼트 | 고객 가치(전체 평균 매출) | Mean CATE | N (코호트) | 방향 신호 |
|---|---|---|---|---|
| VIP Heavy | $9,716 (최고) | -$38 | 59 | 축소 / TypeA 제외 |
| Bulk Shoppers | $3,206 | -$40 | 77 | 축소 / TypeA 제외 |
왜 고가치 고객이 음의 CATE를 보이는가?
| 세그먼트 | 원인 분석 |
|---|---|
| VIP Heavy | 이미 High Purchaser → Ceiling Effect, 쿠폰이 기존 구매를 대체 (Cannibalization) |
| Bulk Shoppers | 쿠폰 기반 TypeA가 비정기 대량 구매 쇼핑 리듬과 미스매치 |
비즈니스 임팩트(분석 코호트 486명 기준, 가설 생성적):

Results Summary
Track 1 Results: Latent Factor Modeling + Clustering
5개 Latent Factor 해석(NMF k=5, 분산 설명 92.44%):
| Factor | 명칭 | 상위 Feature (loading) | 해석 |
|---|---|---|---|
| F1 | Grocery Deal Seeker | share_grocery(6.72), discount_usage_pct(5.13), private_label_ratio(3.41) | 할인 추구 예산 중시 |
| F2 | Loyal Regular | purchase_regularity(4.63), n_departments(2.61), n_products(1.53), frequency(1.04) | One-stop 고관여 (Value) |
| F3 | Big Basket | monetary_std(2.45), monetary_avg_basket(2.35), share_grocery(2.08) | 비정기 대량 구매 (Value) |
| F4 | Fresh Focused | share_fresh(2.26), n_departments(1.21) | 신선식품 전문가 (Need) |
| F5 | Health & Beauty | share_health_beauty(2.03), recency(0.41) | 드럭스토어 유형 (Need) |
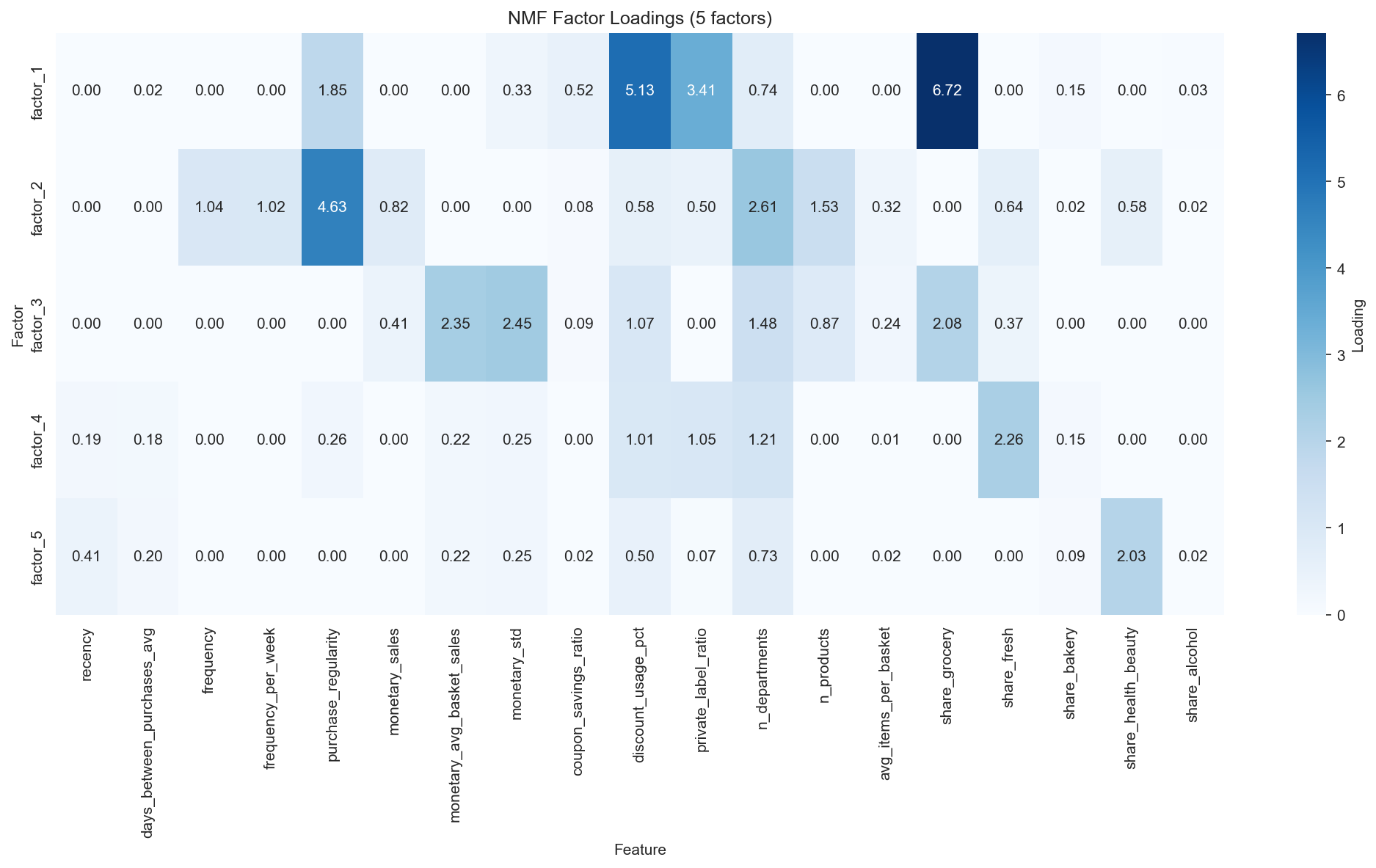 5개 Latent Factor의 Feature Loading. F2(Loyal)와 F3(Big Basket)이 Value 차원, F4(Fresh)와 F5(H&B)가 Need 차원을 포착한다.
5개 Latent Factor의 Feature Loading. F2(Loyal)와 F3(Big Basket)이 Value 차원, F4(Fresh)와 F5(H&B)가 Need 차원을 포착한다.
Clustering 평가 메트릭(요약):
| 메트릭 | 값 | 해석 |
|---|---|---|
| Explained Variance | 92.44% | 높은 Factor 커버리지 |
| Silhouette Score (k=7) | 0.219 | 행동 데이터로서 적절 (전역 최댓값은 아님 — 부록 참조) |
| Calinski-Harabasz (k=7) | 732.0 | — |
| Davies-Bouldin Index (k=7) | 1.241 | k 후보 중 최소(최적 분리) |
| Bootstrap ARI | 0.77 ± 0.11 (n=100) | 높은 세그먼트 안정성 |
k 선택의 정직한 근거: Silhouette는 실제로 낮은 k(k=3=0.271)에서 가장 높다. k=7은 DBI 최소(1.241) + 비즈니스 해석가능성/실행가능성 + 높은 부트스트랩 안정성(ARI 0.77) 을 근거로 선택했다. “Silhouette가 k=7에서 최고”라고 주장하지 않는다. (전체 grid는 Track 1 리포트 부록).
7개 고객 세그먼트(전체 2,500명 기준):
| Seg | 명칭 | 규모 | 평균 매출 | Frequency(방문) | Recency(일) | Regularity | 주요 Factor |
|---|---|---|---|---|---|---|---|
| 0 | Active Loyalists | 509 (20.4%) | $3,878 | 171 | 6 | 0.78 | F2 (Loyal) |
| 1 | VIP Heavy | 299 (12.0%) | $9,716 | 256 | 4 | 0.88 | F2 (Loyal) |
| 2 | Lapsed H&B | 193 (7.7%) | $872 | 37 | 75 | 0.25 | F5 (H&B) |
| 3 | Fresh Lovers | 339 (13.6%) | $1,233 | 48 | 36 | 0.34 | F4 (Fresh) |
| 4 | Light Grocery | 524 (21.0%) | $942 | 43 | 42 | 0.30 | F1 (Grocery-Deal) |
| 5 | Bulk Shoppers | 318 (12.7%) | $3,206 | 56 | 24 | 0.41 | F3 (Basket) |
| 6 | Regular + H&B | 318 (12.7%) | $3,393 | 152 | 12 | 0.70 | F2 (Loyal) |
Light Grocery(Seg 4)는 grocery share(0.56) + discount(0.51)가 F1(Grocery-Deal) 에 적재되어 주요 Factor를 F1으로 표기한다.
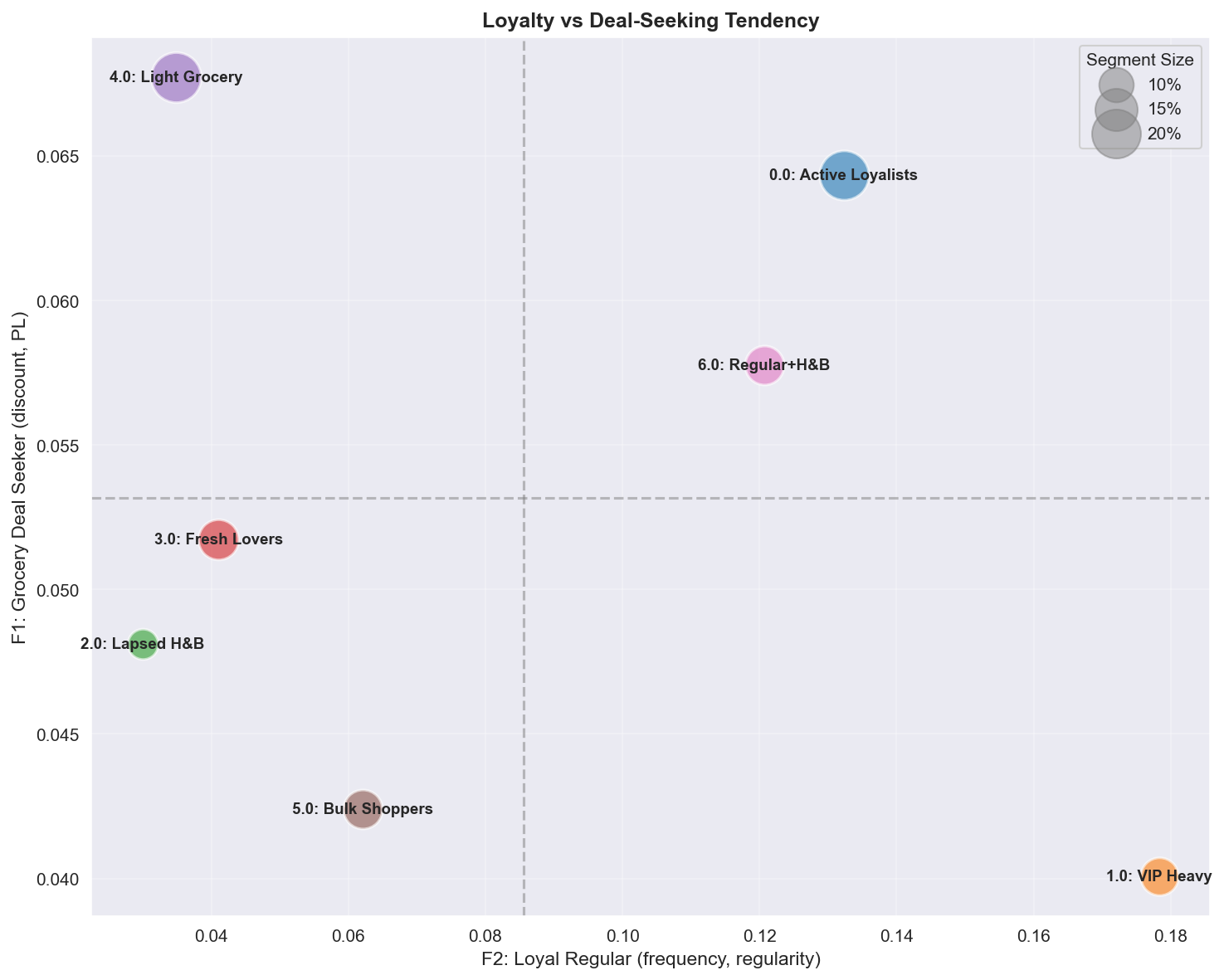 충성도(F2) × 할인추구(F1) 2D 공간의 7개 세그먼트. VIP Heavy(고충성·저할인=프리미엄)와 Active Loyalists(고충성·고할인=예산 중시 충성)는 같은 ‘충성’이라도 할인 반응이 정반대다 — 이 포지셔닝 차이가 Track 2에서 세그먼트별 CATE가 갈리는 행동적 토대가 된다.
충성도(F2) × 할인추구(F1) 2D 공간의 7개 세그먼트. VIP Heavy(고충성·저할인=프리미엄)와 Active Loyalists(고충성·고할인=예산 중시 충성)는 같은 ‘충성’이라도 할인 반응이 정반대다 — 이 포지셔닝 차이가 Track 2에서 세그먼트별 CATE가 갈리는 행동적 토대가 된다.
세그먼트별 마케팅 전략 (Track 1 기반):
| 세그먼트 | 우선순위 | 전략 | 주요 액션 |
|---|---|---|---|
| VIP Heavy | High | Retention | 프리미엄 혜택, Churn 예측, 독점 접근 |
| Active Loyalists | High | Strengthen | PB 프로모션, 로열티 포인트, 장바구니 확대 |
| Regular + H&B | Medium | Upgrade | VIP 전환 프로그램, Cross-category 인센티브 |
| Bulk Shoppers | Medium | Regularize | 구독 제안, 정기 배송, 번들 딜 |
| Fresh Lovers | Medium | Engage | 신선식품 콘텐츠, 일일 특가, 레시피 |
| Light Grocery | Low | Activate | 습관 형성 캠페인, 점진적 보상 |
| Lapsed H&B | Low | Win-back | 재관여 캠페인, H&B 집중 오퍼 |
💡 Track 1 vs Track 2 전략 차이: Track 1은 고객 특성 기반 일반 전략, Track 2는 CATE 기반 TypeA 캠페인 타겟팅 전략이다. VIP Heavy는 Track 1에서 “Retention”이지만, Track 2에서는 TypeA 타겟팅 “축소” 권고로 갈린다.
Track 2 Results: CATE 및 최적 타겟팅
ATE 추정 (방법별, n=2,430):
| 방법 | ATE | 95% CI | 신뢰성 |
|---|---|---|---|
| Naive | +$471 | [$442, $501] | ❌ 상향 편향 |
| IPW | +$151 | [-$10, $313] | ⚠️ 불안정 |
| AIPW | +$24 | [-$56, $104] | ✅ Doubly-robust |
| OLS | +$65 | [$29, $102] | — |
| DML | -$65 | [-$220, $90] | ⚠️ 방향 반전 |
| ATO (Overlap) | +$60 | [-$14, $134] | ✅ Overlap 집중 |
방법 간 추정치가 -$65 ~ +$471로 크게 흩어진다 — 이는 Positivity Violation의 직접적 증상이며, Overlap 집중 추정치(ATO +$60)와 doubly-robust 추정치(AIPW +$24)를 더 신뢰한다.
CATE 모델 성과 (main run; test set):
| 모델 | 평균 CATE | Test Std | AUUC | % positive | 선택 |
|---|---|---|---|---|---|
| CausalForestDML | +$15 | $52 | 271.6 | 78% | ✅ Primary |
| LinearDML | -$139 | $452 | 357.0 | 42% | ❌ 최고 AUUC이나 불안정 |
| NonParamDML | +$1.1M (발산) | 매우 큼 | 304.4 | 64% | ❌ 발산 |
| S-Learner | -$21 | $46 | 289.5 | 21% | ❌ 79% 음수효과(비현실적) |
| X-Learner | -$96 | $208 | 218.5 | 38% | ❌ 높은 분산 |
| T-Learner | -$200 | $397 | 212.0 | 43% | ❌ 높은 분산 |
모델 선택 근거(정직한 reframe): CausalForestDML은 AUUC 최고가 아니다. main run에서 AUUC 최고는 LinearDML(357.0) 이고 CausalForestDML은 4위(271.6)다. 그럼에도 CausalForestDML을 1차 모델로 택한 이유는 저분산(std $52 vs LinearDML $452) 과 타당한 CATE 분포(평균 +$10~15, 78% 양수 — 캠페인 목적과 정합) 를 동시에 만족하는 유일한 모델이기 때문이다. AUUC가 더 높은 모델들은 사용 불가하다: LinearDML(평균 -$139, std $452), NonParamDML(발산), S-Learner는 분산은 비슷하나 고객의 79%가 음의 효과라는 비현실적 분포를 함의한다. 심각한 Positivity Violation 하에서는 raw AUUC보다 안정성·타당성을 우선한다. (보조 근거: BLP test p=0.094 경계, X-Learner p=0.005 — 이질성 신호는 약하다. 자세히는 Track 2 보고서.) 전체 코호트(486명)에 대한 CausalForestDML 평균 CATE는 +$10으로 일관된다.
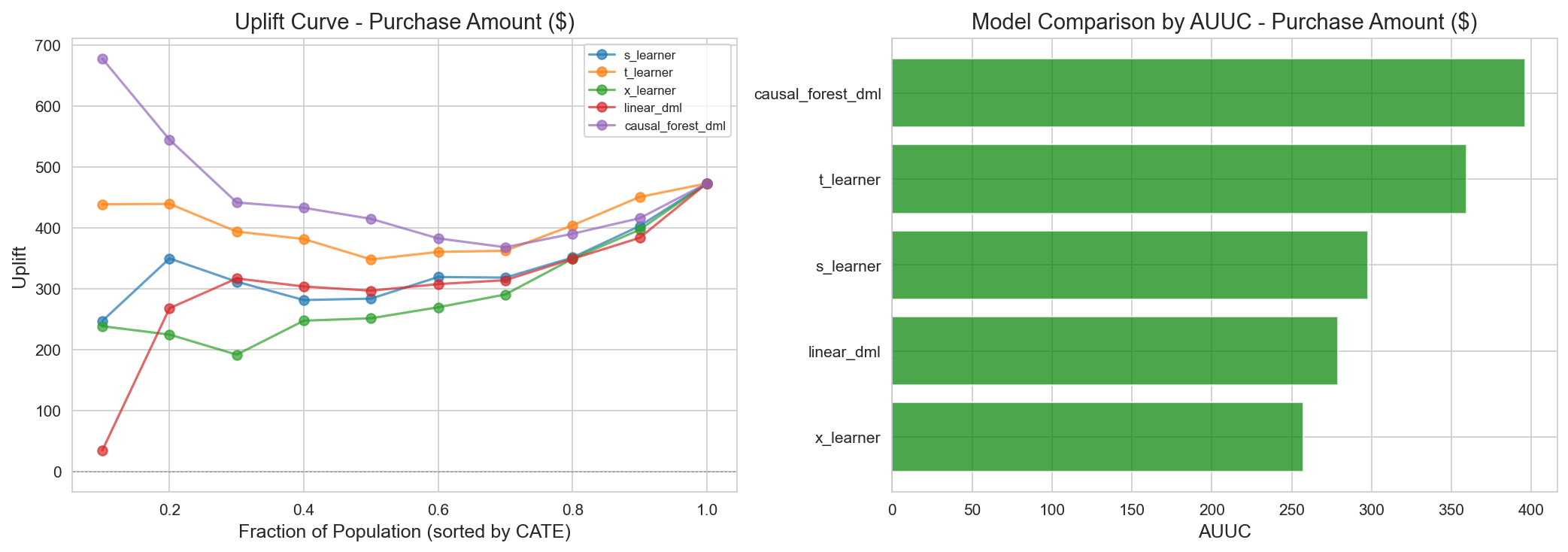 CATE 모델별 AUUC 비교. 안정성·타당성 기준으로 선택된 CausalForestDML의 uplift 곡선. 상위 30% 타겟팅 시 $2,200+ 추가 수익 예상.
CATE 모델별 AUUC 비교. 안정성·타당성 기준으로 선택된 CausalForestDML의 uplift 곡선. 상위 30% 타겟팅 시 $2,200+ 추가 수익 예상.
세그먼트별 CATE 및 권장 액션
N은 Track 2 분석 코호트(486명) 기준이며 Track 1 전체 세그먼트 규모와 다르다. “현재/권장 타겟팅 %“는 원천 CSV에 없는 값이므로 방향성(확대/유지/축소) 으로만 제시한다.
| 세그먼트 | N (코호트) | Mean CATE | 권장 액션 (방향) |
|---|---|---|---|
| Active Loyalists | 97 | +$33 | Test & Learn (소폭 확대) |
| Regular + H&B | 62 | +$34 | Test & Learn (소폭 확대) |
| Light Grocery | 91 | +$30 | Test & Learn (확대) |
| Fresh Lovers | 73 | +$27 | Test & Learn (확대) |
| Lapsed H&B | 27 | +$19 | Test & Learn |
| VIP Heavy | 59 | -$38 | 축소 / TypeA 제외 |
| Bulk Shoppers | 77 | -$40 | 축소 / TypeA 제외 |
세그먼트별 CATE 분포. VIP Heavy(-$38)와 Bulk Shoppers(-$40)의 음의 효과가 명확하다.
Policy 비교 분석 (486 코호트)
| Policy | 기준 | Target % (N) | Profit | ROI | 특징 |
|---|---|---|---|---|---|
| CATE > Breakeven | Point est. > $42.43 | 31.3% (152) | +$2,426 | 125% | ✅ 최적 |
| Top 20% CATE | Percentile | 20.0% (97) | +$2,259 | 183% | 예산 제약 시 최고 ROI |
| Conservative | Lower CI > $42.43 | 0.6% (3) | +$188 | 493% | 초보수(A/B 전) |
| Risk-Adjusted (30%) | 위험 조정 | 11.1% (54) | +$1,603 | 233% | 분산 페널티 |
| PolicyTree (Tuned) | 학습된 규칙 | 26.7% (130) | +$1,684 | 102% | 해석 가능 |
| CATE > 0 | Point est. > 0 | 64.6% (314) | +$1,447 | 36% | 느슨한 규칙 |
| 현행 관행 | — | 62.1% (302) | -$3,402 | -88% | ❌ 손실 |
| 전체 타겟팅 | — | 100% (486) | -$4,659 | -75% | ❌ 손실 |
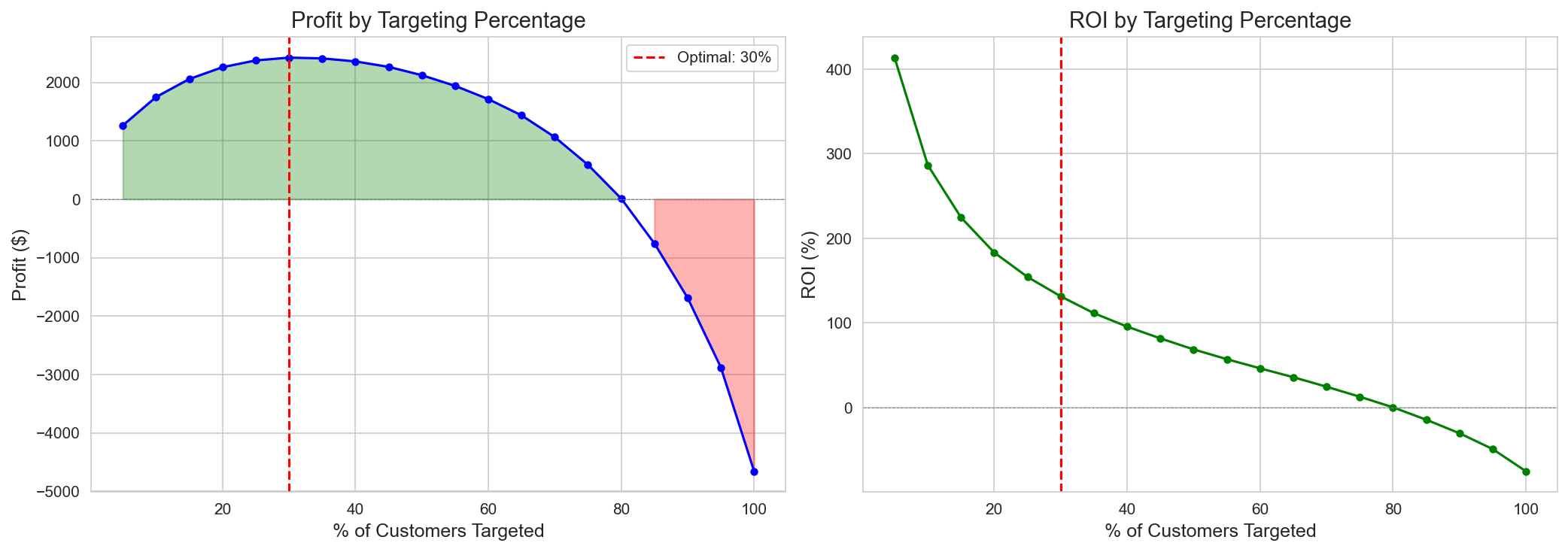 *CATE 상위 고객부터 누적 타겟팅하면 약 **31%*에서 ROI가 정점(+$2,426 / 125%)을 찍고, 이후 음(−)의 CATE 고객이 더해지며 곡선이 꺾여 100% 타겟팅에선 손실(−$4,659)로 전환된다. “누구를 빼느냐”가 “누구를 넣느냐”만큼 중요함을 한 장으로 보여준다.
*CATE 상위 고객부터 누적 타겟팅하면 약 **31%*에서 ROI가 정점(+$2,426 / 125%)을 찍고, 이후 음(−)의 CATE 고객이 더해지며 곡선이 꺾여 100% 타겟팅에선 손실(−$4,659)로 전환된다. “누구를 빼느냐”가 “누구를 넣느냐”만큼 중요함을 한 장으로 보여준다.
Limitations & Lessons Learned
| 한계 | 증거 | 완화책 |
|---|---|---|
| Positivity Violation | PS AUC = 0.989, Overlap 17% | PS Trimming, ATO Weighting, Manski Bounds, 부분 식별 |
| Refutation Test 실패 | Placebo(Amount) 0.747 (>0.5 → FAIL), Subset Stability 0.561 (<0.7 → FAIL) | A/B Test 검증 설계 (n=5,748) |
| 모델 불일치 | CausalForest +$10 vs LinearDML -$139 | 안정성·타당성 기준 선택, 방향 불일치 인정 |
| 단일 캠페인 유형 | TypeA만 분석 | TypeB/C 별도 분석 필요 |
Refutation은 실패했다 — 그리고 그것은 예상된 결과다. Placebo Treatment(Amount)=0.747(임계 <0.5)와 Subset Stability=0.561(임계 >0.7)은 모두 임계를 통과하지 못했다(단, Placebo-Visits=0.052는 통과). 이는 Positivity Violation 하에서 예상되는 신호이며, 결과를 확증적이 아닌 가설 생성적으로 다뤄야 함을 뒷받침한다. 결과는 숨기거나 완화하지 않는다.
교훈
“PS AUC 0.989는 Observational Study의 근본적 한계를 보여준다. 결과를 **가설 생성적(hypothesis-generating)**으로 해석하고, A/B Test로 검증 후 배포해야 한다.”
향후 방향
- A/B Test 검증: n=5,748 (2,874/arm, 80% Power, α=0.05, 탐지 가능 효과 ~$34)으로 가설 검증.
- ε-greedy Exploration: 모든 고객에 최소 ε 확률로 treatment 할당 → Positivity 보장.
- MLOps 확장: CATE 모니터링 대시보드, 모델 재훈련 파이프라인.