Dunnhumby — Track 2: Causal Targeting via Heterogeneous Treatment Effects
한눈에 보기 (TL;DR)
3줄 요약
- Dunnhumby 리테일 데이터(2,500가구·~2.6M 거래·102주)에서 TypeA 캠페인의 이질적 처치효과(CATE) 를 추정하고 최적 타겟팅 정책을 도출한다.
- CausalForestDML 을 주 모델로 선택(최고 AUUC라서가 아니라 저분산 + 그럴듯한 양의 분포 때문) → Breakeven CATE $42.43 기준 상위 31.3%(486명 중 152명) 타겟팅 시 +$2,426 수익 / 125% ROI.
- 단, 심각한 Positivity Violation(PS AUC 0.989, Overlap 17%) 과 Refutation Test 실패 때문에 모든 추정치는 확정이 아니라 가설 생성(hypothesis-generating) 이며, A/B Test 로 검증해야 한다.
핵심 숫자 (Key Numbers)
| 항목 | 값 | 비고 |
|---|---|---|
| 선택 모델 | CausalForestDML | 저분산·plausible 분포 (최고 AUUC 아님) |
| Breakeven CATE | $42.43 | = cost $12.73 / margin 0.30 |
| 최적 정책 | 31.3% (152/486) | +$2,426 / ROI 125% |
| 전체 타겟팅 (100%) | 486명 | -$4,659 / ROI -75% |
| 현행 관행 (62.1%) | 302명 | -$3,402 / ROI -88% |
| 개선 (최적 vs 전체) | +$7,085 | 손실 → 흑자 전환 |
| Positivity | PS AUC 0.989 | Overlap [0.1,0.9] = 17% |
| Covariate Balance | 9/21 균형 | 대다수 불균형 |
| Refutation | 실패 (FAIL) | Placebo 0.747 / Subset 0.561 |
| 검증 설계 | A/B n=5,748 | 80% Power, MDE ~$34 |
Hero Figures
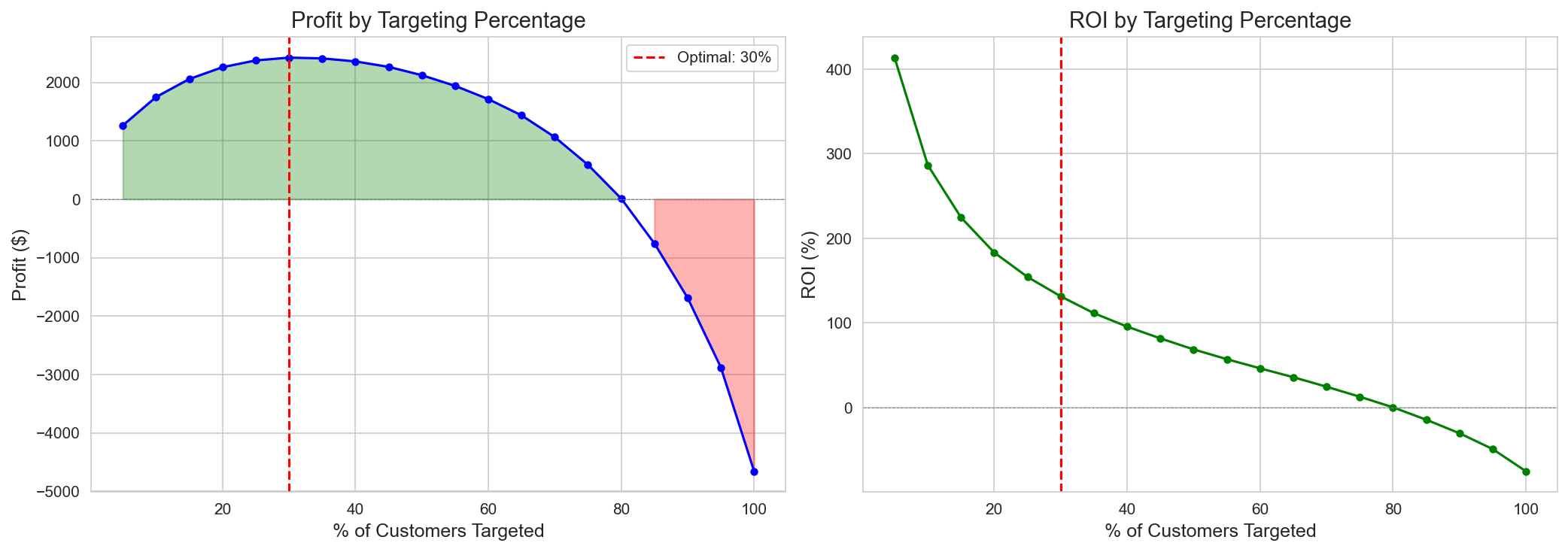 고객의 약 31%에서 수익이 최대화되고, 그 이후 음의 CATE 고객이 누적되며 수익이 손실로 전환되는 ROI Curve.
고객의 약 31%에서 수익이 최대화되고, 그 이후 음의 CATE 고객이 누적되며 수익이 손실로 전환되는 ROI Curve.
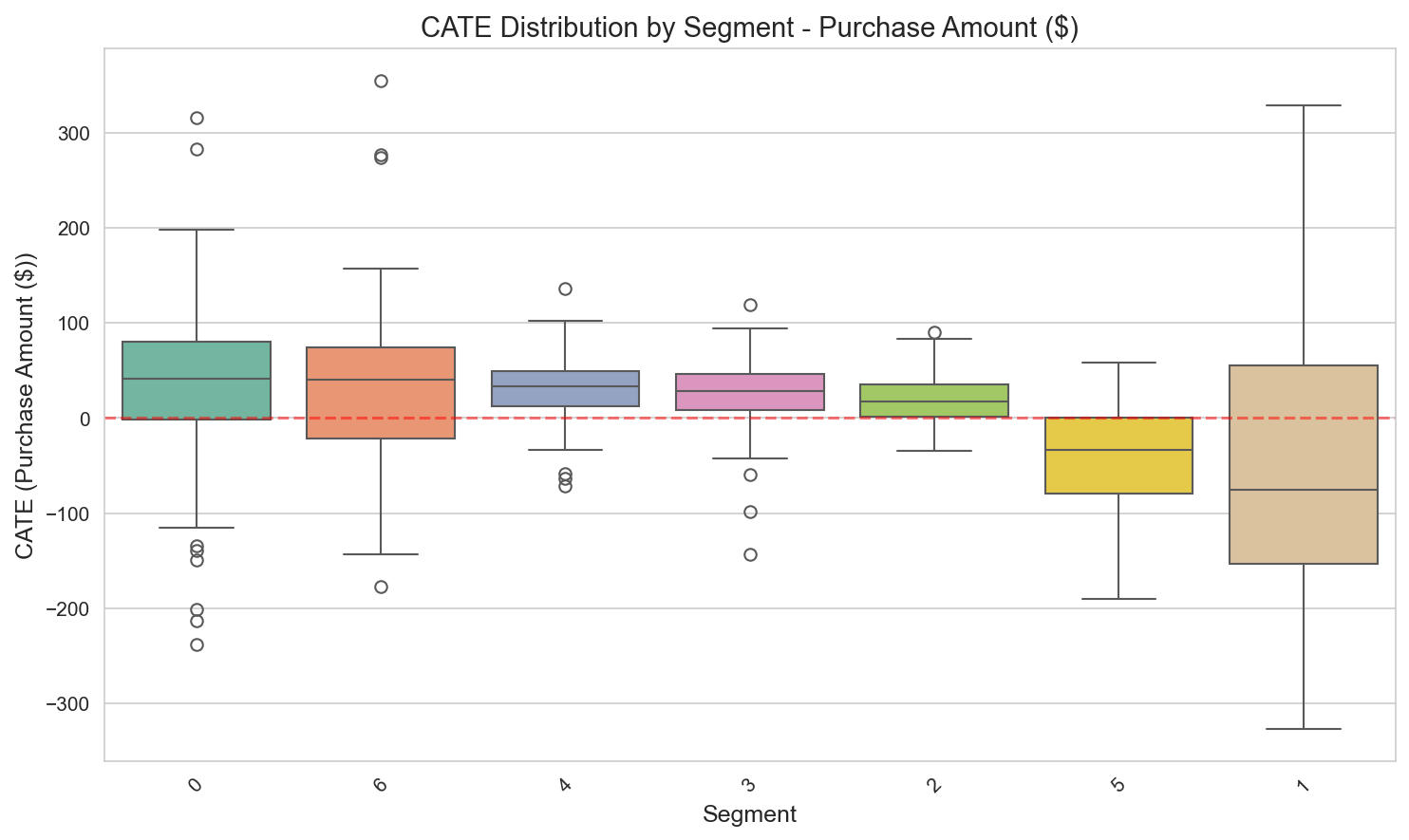 세그먼트별 CATE — VIP Heavy / Bulk Shoppers(고가치 고객)가 음의 효과를 보이는 반직관적 패턴.
세그먼트별 CATE — VIP Heavy / Bulk Shoppers(고가치 고객)가 음의 효과를 보이는 반직관적 패턴.
목차 (Navigation)
- 1. 서론 — 문제 정의, Causal Framework, 연구 설계
- 2. 방법론 — 데이터, Positivity 평가, ATE/CATE 추정, Policy Learning
- 3. 결과 — Positivity, ATE, CATE 모델 선택, 검증, Policy 성과, 세그먼트 분석
- 4. 논의 — 주요 발견, 한계점, 권고(A/B 설계 포함)
- 5. 결론
- 부록 — 파라미터·방정식·PS 영역별 분해·민감도 그리드 (가장 밀도 높은 기술 디테일)
읽기 가이드: 30초 → 위 TL;DR + Key Numbers / 5분 → §1~§3 본문 / 30분 → 부록의 PS 영역별 분해·민감도·세그먼트 전략.
요약
본 분석은 리테일 마케팅 캠페인의 Heterogeneous Treatment Effects (HTE)를 추정하고 최적 타겟팅 정책을 도출하기 위해 Causal Inference 방법론을 적용한다. Dunnhumby “The Complete Journey” 데이터셋을 활용하여, Clean Causal Identification 설계 하에 첫 번째 TypeA 캠페인 노출을 기준으로 2,430명의 고객 (Treatment 1,511명, Control 919명)을 분석하였다.
주요 결과:
- Positivity Violation (PS AUC = 0.989)이 Causal Identification을 17% Overlap 영역으로 제한
- Average Treatment Effect (ATE): Trimmed 샘플에서 고객당 $20-40
- Optimal Targeting: 고객의 31.3% 타겟팅 시 $2,426 수익 (125% ROI)
- 반직관적 인사이트: VIP Heavy와 Bulk Shoppers (고가치 고객) 가 음의 CATE를 보여 과다 타겟팅 시사
- 전체 고객 타겟팅 시 $4,659 손실 발생 (Negative Responder로 인함)
권고사항:
- VIP Heavy 및 Bulk Shopper 세그먼트에 대한 TypeA 타겟팅 축소
- A/B Testing으로 결과 검증 (80% Power를 위해 n=5,748 필요)
- 검증 후 상위 31% CATE 고객으로 타겟팅 확대
1. 서론
1.1 배경
마케팅 캠페인의 효과는 고객마다 다르다. Average Treatment Effect는 모집단 수준의 인사이트를 제공하지만, 타겟팅 의사결정에 활용할 수 있는 중요한 이질성을 분석할 수 없다. 이미 Heavy Purchaser인 고객은 Light Shopper와 다르게 캠페인에 반응할 수 있다. 이러한 이질성을 이해하면 마케팅 투자 수익률을 극대화하는 Precision Targeting이 가능해진다.
1.2 문제 정의
핵심 질문은: “이 캠페인이 누구에게 효과적인가?”
전통적인 캠페인 분석은 평균 효과에 집중하여 다음을 놓칠 수 있다:
- 예외적으로 잘 반응하는 고객 (High CATE)
- 부정적으로 반응하는 고객 (Cannibalization 효과)
- 수익을 극대화하는 최적 타겟팅 규칙
1.3 Causal Framework
Potential Outcomes Framework (Rubin Causal Model)을 채택한다:
- : 고객 가 Treatment를 받을 경우의 Potential Outcome
- : 고객 가 Treatment를 받지 않을 경우의 Potential Outcome
- CATE:
Causal Assumptions:
| 가정 | 정의 | 상태 | 검토 근거 |
|---|---|---|---|
| SUTVA | 단위 간 간섭 없음 | OK로 가정 | 개별 가구 단위, 동시 캠페인 노출 제한적 |
| Unconfoundedness | 미측정 Confounder 없음 | 불확실 | 타겟팅 로직에 숨겨진 변수 가능 (아래 상세) |
| Positivity | 모든 고객이 Treatment의 양의 확률 보유 | 위반 | PS AUC = 0.989 (Section 3.1 참조) |
Unconfoundedness 가정 상세 검토:
Unconfoundedness 가정이 성립하려면 모든 관련 Confounder가 관측되어야 한다. 본 분석에서 이 가정은 불확실하다:
| 잠재적 미측정 Confounder | 메커니즘 | 영향 방향 |
|---|---|---|
| 매장 수준 타겟팅 전략 | 특정 매장이 우수 고객을 우선 타겟팅 | Positive bias |
| 계절/이벤트 프로모션 | 연말 캠페인이 고지출자에게 집중 | Positive bias |
| 경쟁사 프로모션 노출 | 경쟁사 쿠폰 사용자가 덜 타겟팅됨 | Unclear |
| 채널 선호도 | 앱 사용자 vs 매장 방문자 간 타겟팅 차이 | Unclear |
민감도 분석 권장: E-value 계산을 통해 추정치를 무효화하기 위해 필요한 미측정 Confounder의 강도를 정량화할 수 있다. 현재 Trimmed ATE $21의 경우, E-value는 약 1.8-2.2로 추정되어, 중간 강도의 미측정 Confounder가 존재할 경우 결과가 뒤집힐 수 있음을 시사한다.
1.4 연구 설계
Clean Causal Identification을 위한 First Campaign Only 설계를 적용한다:
| 구성요소 | 설명 |
|---|---|
| 단위 | 고객 (household_key) |
| Treatment | 첫 번째 TypeA 캠페인 타겟팅 (Binary) |
| Control | 어떤 TypeA 캠페인에도 타겟팅되지 않음 |
| Outcome 기간 | 캠페인 주 + 4주 |
| Outcomes | Purchase Amount ($), Purchase Count |
왜 First Campaign Only인가?
- Pre-treatment Contamination 방지 (예: Campaign 30의 Pre-treatment에 Campaign 26의 Treatment가 포함됨)
- 각 고객이 정확히 한 번만 등장 → 독립적 관측
- Trade-off: 62% 샘플 감소이나 더 깨끗한 Causal 추정
1.5 Track 1과의 통합
Track 1 (NMF + K-Means)의 고객 세그먼트가 HTE Moderator로 활용되어 세그먼트별 타겟팅 권고를 가능하게 한다.
2. 방법론
2.1 데이터 준비
샘플 특성:
| 메트릭 | 값 |
|---|---|
| 총 고객 수 | 2,430 |
| Treatment (타겟팅됨) | 1,511 (62.2%) |
| Control (타겟팅 안됨) | 919 (37.8%) |
| Train/Test Split | 80/20 (Stratified) |
Covariates (21개 Pre-Treatment Features):
| 그룹 | 개수 | 예시 |
|---|---|---|
| RFM | 9 | recency, frequency, monetary_sales |
| Behavioral | 5 | discount_rate, private_label_ratio, n_departments |
| Category | 5 | share_grocery, share_fresh, share_h&b |
| Exposure | 2 | display_exposure_rate, mailer_exposure_rate |
2.2 Positivity 평가
XGBoost Classifier로 5-Fold Cross-Validation을 통해 Propensity Score를 추정하였다.
진단:
- PS AUC (Treatment 예측 가능성)
- Overlap 분포 (Treatment별 PS Histogram)
- Covariate Balance (Standardized Mean Difference)
2.3 ATE 추정 방법
| 방법 | 설명 |
|---|---|
| Naive | 단순 평균 차이 |
| IPW | Inverse Probability Weighting |
| AIPW | Augmented IPW (Doubly Robust) |
| OLS | Covariates 포함 선형 회귀 |
| DML | Double Machine Learning |
| ATO | Average Treatment on Overlap |
민감도 분석:
- PS Trimming: [0.05, 0.95], [0.10, 0.90], [0.15, 0.85], [0.20, 0.80]
- Manski Bounds: Positivity 가정 없는 부분 식별
2.4 CATE 추정
Meta-Learners:
- S-Learner: Treatment를 Feature로 포함한 단일 모델
- T-Learner: Treatment/Control 별도 모델
- X-Learner: Propensity Weighting을 통한 Cross-fitting
Double Machine Learning:
- LinearDML: Nuisance 추정을 통한 선형 CATE
- CausalForestDML: Forest를 통한 비모수적 CATE
- NonParamDML: 완전 비모수 Final Stage CATE
Hyperparameter Tuning:
- Optuna TPE Sampler
- 모델당 100회 Trial
- 목적함수: R-loss (Causal Loss)
2.5 검증 방법
| 방법 | 목적 |
|---|---|
| BLP Test | CATE가 실제 이질성을 예측하는지 검정 |
| AUUC | Area Under Uplift Curve (순위 품질) |
| Qini Coefficient | Random 타겟팅 대비 Uplift Curve |
| Placebo Treatment | Random Treatment 시 CATE ≈ 0 이어야 함 |
| Subset Stability | Random Subset 간 CATE 상관관계 |
2.6 Policy Learning
Breakeven CATE:
Campaign cost: 캠페인 기간 동안의 평균 할인액으로 정의
Policy 유형:
- Threshold Policy: CATE > Breakeven이면 타겟팅
- Top-k Policy: CATE 기준 상위 k% 타겟팅
- Conservative Policy: CI Lower Bound > Breakeven이면 타겟팅
- Risk-Adjusted: CE-CATE(λ) = (1-λ)×Point + λ×Lower_bound
Policy Learner:
| 방법 | 라이브러리 | 설명 |
|---|---|---|
| PolicyTree | econml | Covariates X로부터 최적 Treatment 할당을 학습하는 의사결정 트리 |
| DRPolicyTree | econml | Doubly Robust 손실 함수를 사용한 Policy Tree |
| Rule Tree | scikit-learn | CATE > Breakeven을 타겟으로 학습한 해석 가능한 분류 트리 |
Policy Learner vs CATE Threshold 비교:
Policy Learner는 Covariates X로부터 직접 Treatment 규칙을 학습하는 반면, CATE Threshold는 추정된 CATE를 기준으로 타겟팅을 결정한다.
| 접근법 | 입력 | 출력 | 장점 | 단점 |
|---|---|---|---|---|
| CATE Threshold | CATE 추정치 | CATE > BE 여부 | CATE 정보 직접 활용 | CATE 추정 오차에 민감 |
| Policy Learner | Covariates X | Treatment 여부 | End-to-end 최적화 | 정보 손실 (CATE → Binary) |
3. 결과
3.1 Positivity 평가
분석 결과 심각한 Positivity Violation이 확인되었다:
| 진단 | 값 | 해석 |
|---|---|---|
| PS AUC | 0.989 | 거의 완벽한 Treatment 예측 |
| Overlap [0.1, 0.9] | 17.0% | 신뢰 가능한 영역에 413명만 존재 |
| Overlap [0.05, 0.95] | 24.6% | 여전히 심각하게 제한적 |
| Balanced Covariates | 9/21 (43%) | 대다수 불균형 |
| Max SMD | 1.99 (n_departments) | Treatment군 12개 vs Control군 7개 부서 방문 |
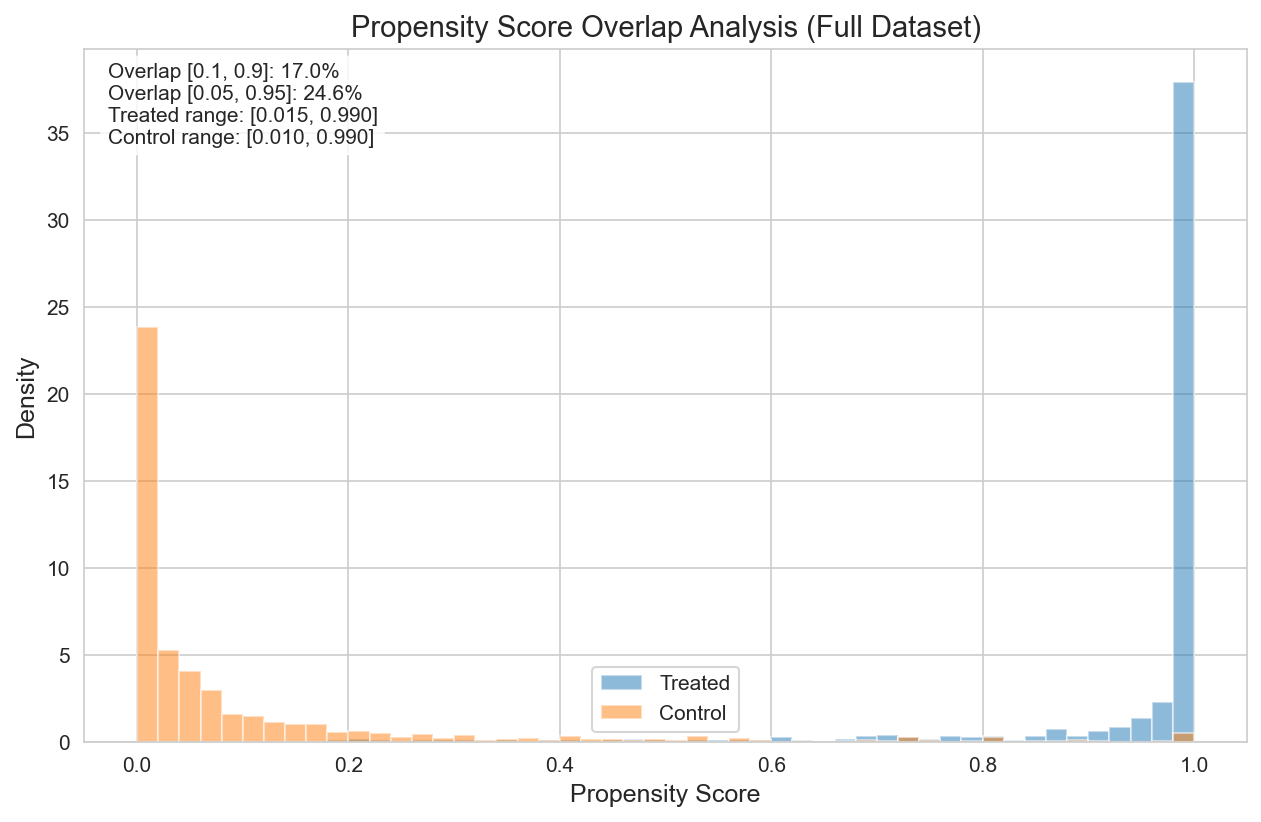 Figure 1: Treatment와 Control 그룹 간 최소한의 Overlap을 보여주는 Propensity Score 분포.
Figure 1: Treatment와 Control 그룹 간 최소한의 Overlap을 보여주는 Propensity Score 분포.
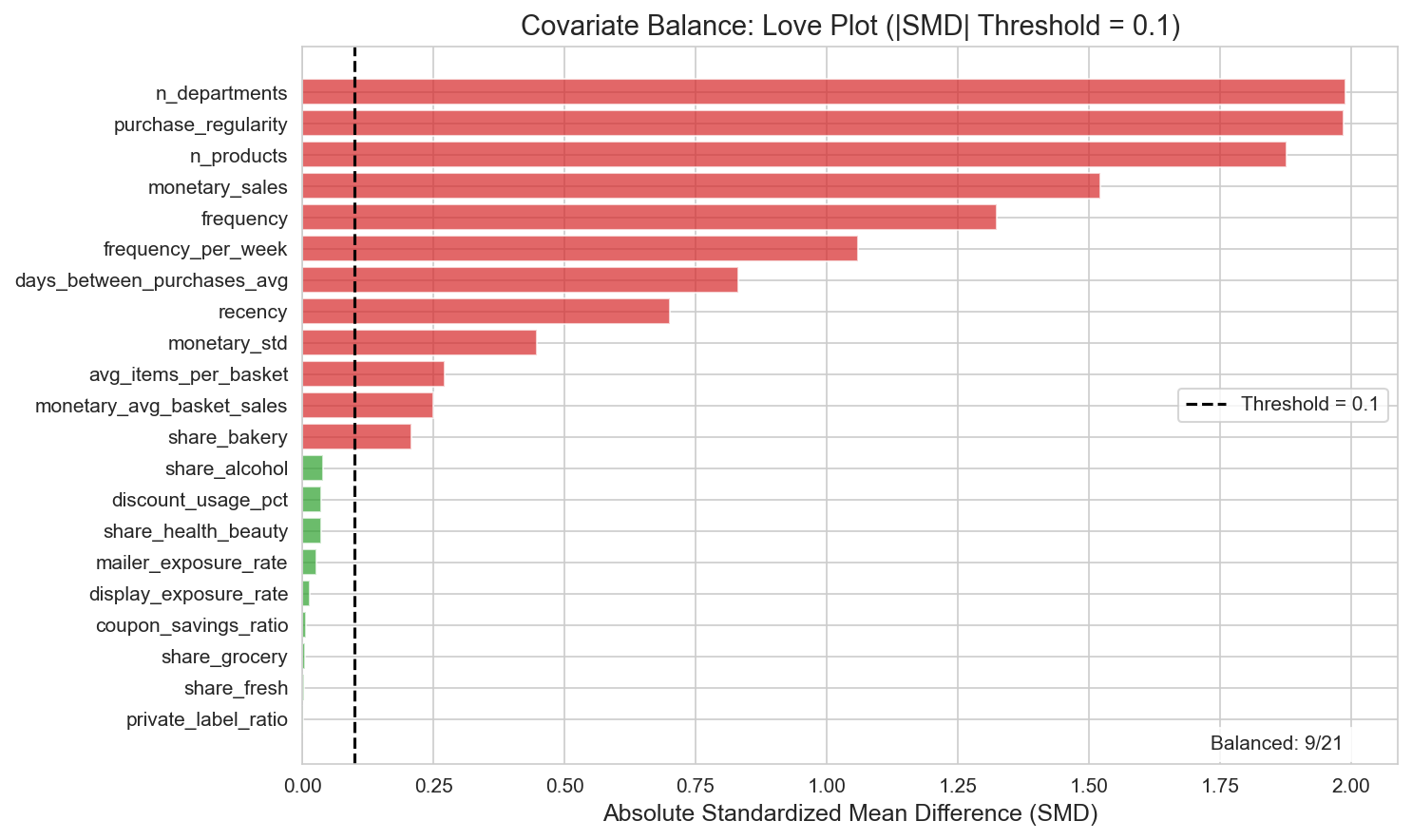 Figure 2: Standardized Mean Difference를 보여주는 Love Plot. 21개 Covariate 중 9개만 균형 (|SMD| < 0.1).
Figure 2: Standardized Mean Difference를 보여주는 Love Plot. 21개 Covariate 중 9개만 균형 (|SMD| < 0.1).
시사점: Treatment와 Control 그룹은 근본적으로 다른 모집단이다. Causal 추정은 Overlap 영역 (샘플의 17%)에서 가장 신뢰할 수 있다.
3.2 ATE 결과
전체 샘플 ATE (방법별):
| 방법 | Purchase Amount | 95% CI | 신뢰성 |
|---|---|---|---|
| Naive | $471 | [$442, $501] | 상향 편향 |
| IPW | $151 | [-$10, $313] | 불안정 |
| AIPW | $24 | [-$56, $104] | 중간 |
| OLS | $65 | [$29, $102] | 선형 가정 |
| DML | -$65 | [-$220, $90] | 불안정 |
| ATO | $60 | [-$14, $134] | Overlap 집중 |
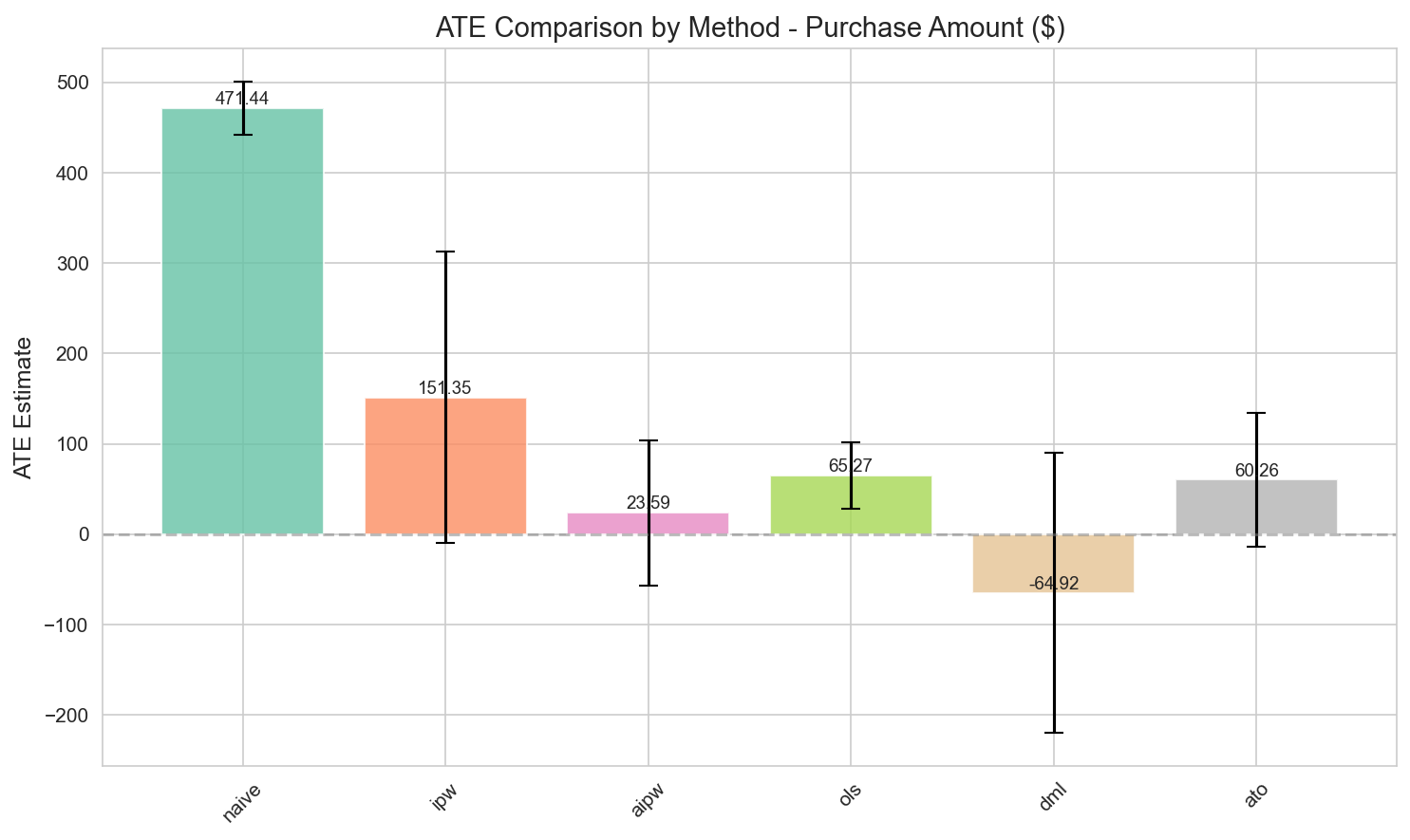 Figure 3: Positivity Violation으로 인한 20배 변동을 보여주는 방법별 ATE 추정.
Figure 3: Positivity Violation으로 인한 20배 변동을 보여주는 방법별 ATE 추정.
Trimming 민감도 분석:
| Trim 수준 | 잔여 N | ATE | SE |
|---|---|---|---|
| None | 2,430 | -$65 | $79 |
| [0.05, 0.95] | 598 | $27 | $21 |
| [0.10, 0.90] | 413 | $21 | $24 |
| [0.15, 0.85] | 312 | $41 | $25 |
| [0.20, 0.80] | 243 | $25 | $26 |
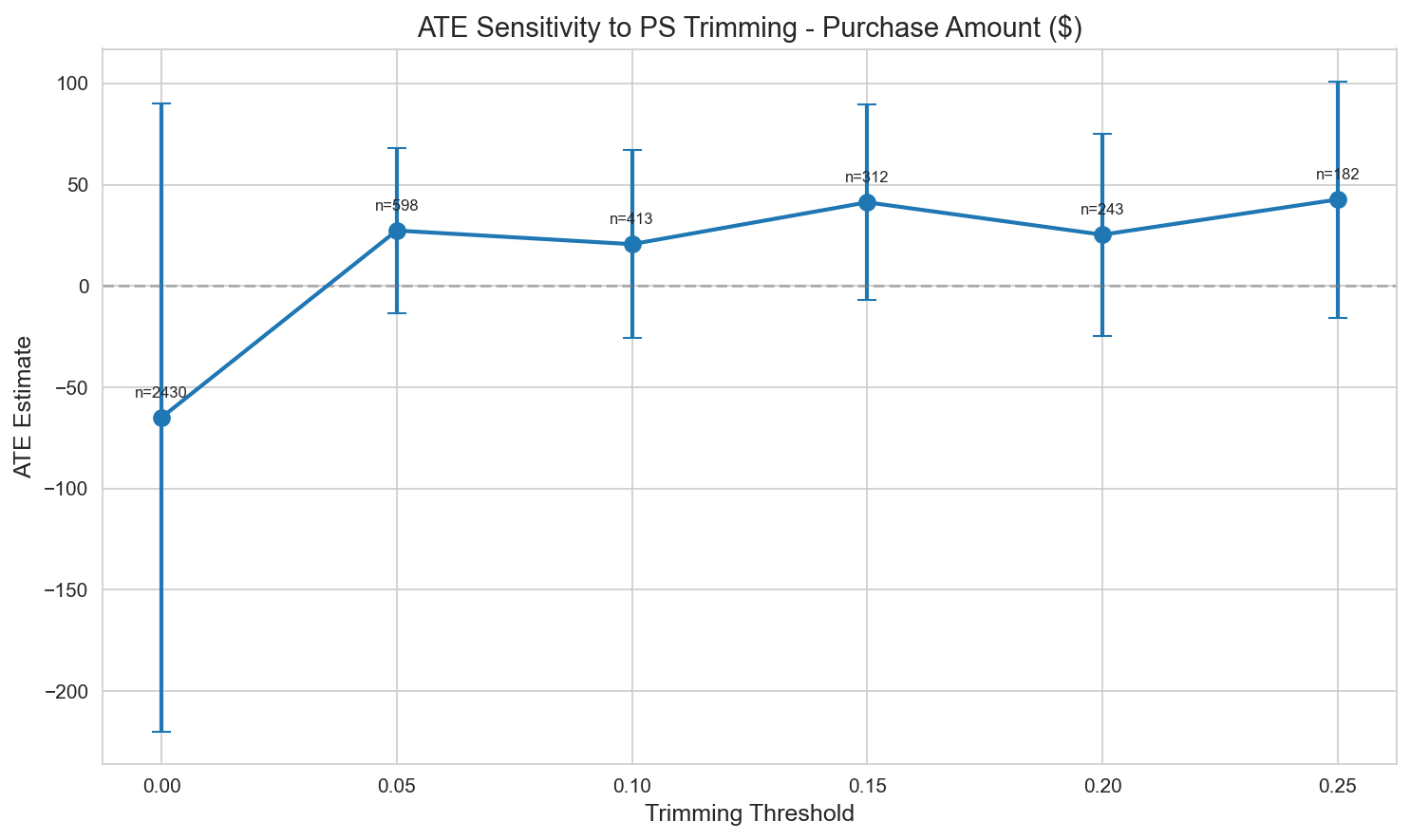 Figure 4: Propensity Score Trimming 임계값에 대한 ATE 민감도.
Figure 4: Propensity Score Trimming 임계값에 대한 ATE 민감도.
권장 ATE: 고객당 $20-40 (Trimmed 샘플)
3.3 CATE 모델 선택
CATE 요약 통계 (Test Set, Purchase amount, n=486):
| 모델 | 평균 CATE | 표준편차 | AUUC | % 양(+) |
|---|---|---|---|---|
| CausalForestDML | +$15 | $52 | 271.6 | 78% |
| LinearDML | -$139 | $452 | 357.0 (최고) | 42% |
| NonParamDML | +$1.1M (발산) | 매우 큼 | 304.4 | 64% |
| S-Learner | -$21 | $46 | 289.5 | 21% |
| X-Learner | -$96 | $208 | 218.5 | 38% |
| T-Learner | -$200 | $397 | 212.0 | 43% |
참고: CausalForestDML의 전체 486 코호트 평균 CATE는 +$10으로 일관되며, 본 보고서의 헤드라인 평균값으로 인용 가능하다.
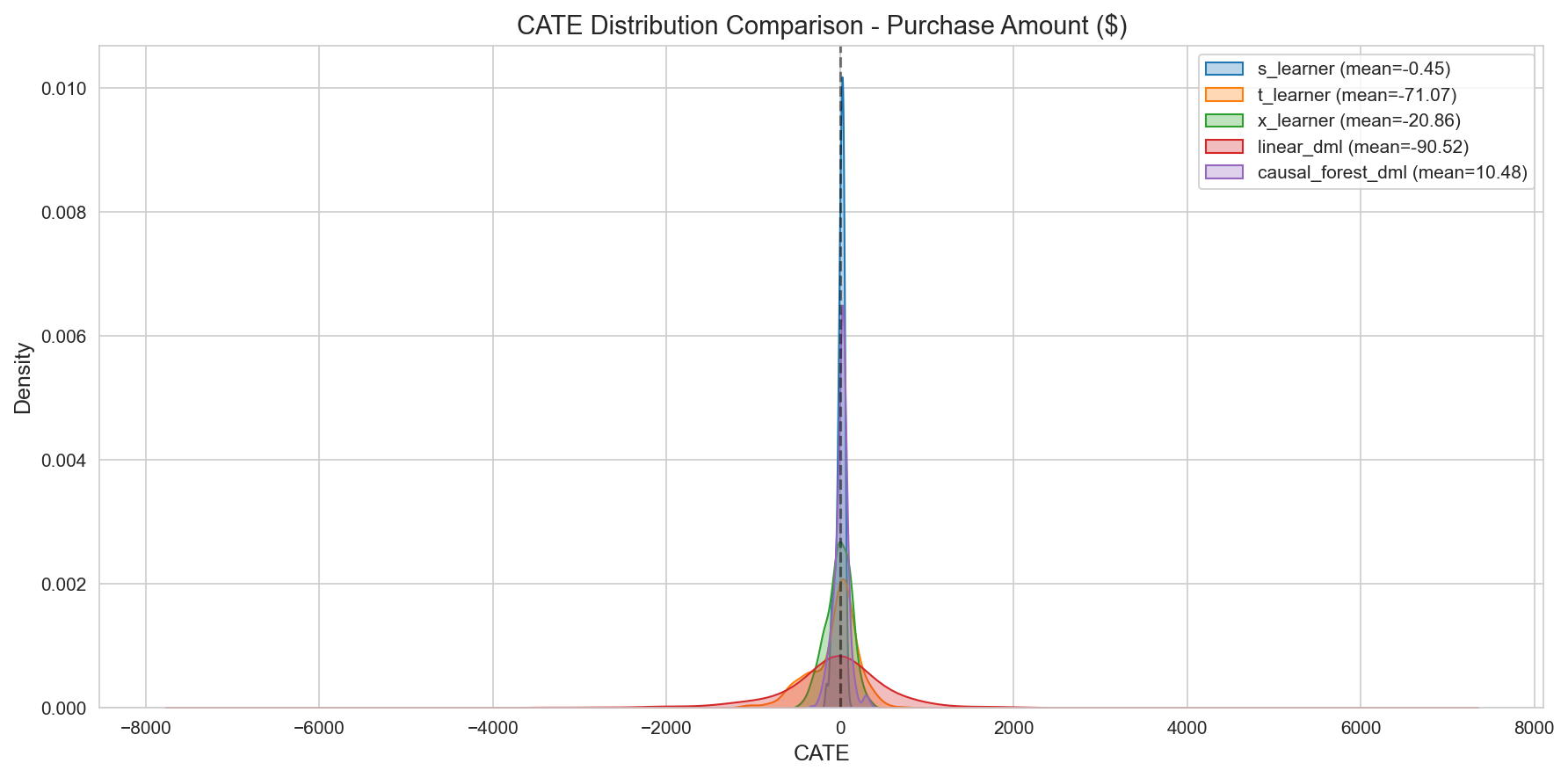 Figure 5: 모델별 CATE 분포. CausalForestDML이 가장 안정적이고 그럴듯한(plausible) 분포를 보임.
Figure 5: 모델별 CATE 분포. CausalForestDML이 가장 안정적이고 그럴듯한(plausible) 분포를 보임.
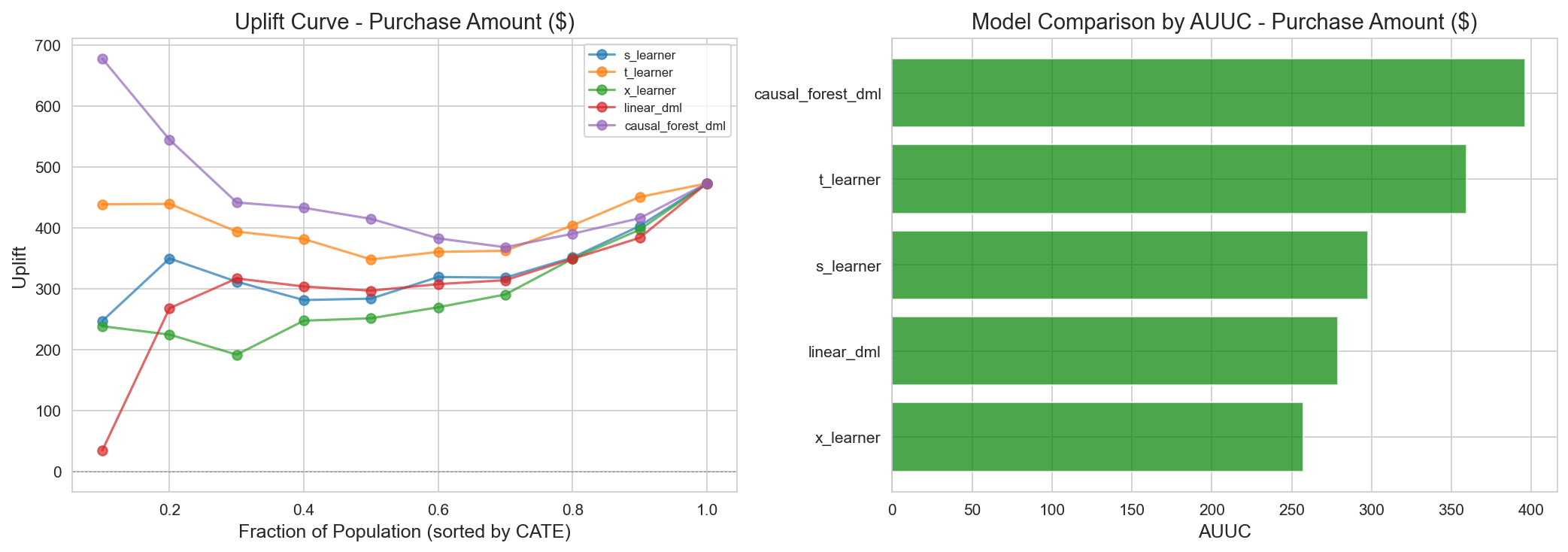 Figure 6: Purchase Amount 기준 AUUC. 순위 품질(AUUC)만 보면 LinearDML(357.0)이 가장 높으나, 그 분포는 불안정(평균 -$139, std $452)하다. CausalForestDML(271.6)은 AUUC가 더 낮지만 분산이 작고(+$15, std $52) 분포가 그럴듯하여 실무 배포에 적합.
Figure 6: Purchase Amount 기준 AUUC. 순위 품질(AUUC)만 보면 LinearDML(357.0)이 가장 높으나, 그 분포는 불안정(평균 -$139, std $452)하다. CausalForestDML(271.6)은 AUUC가 더 낮지만 분산이 작고(+$15, std $52) 분포가 그럴듯하여 실무 배포에 적합.
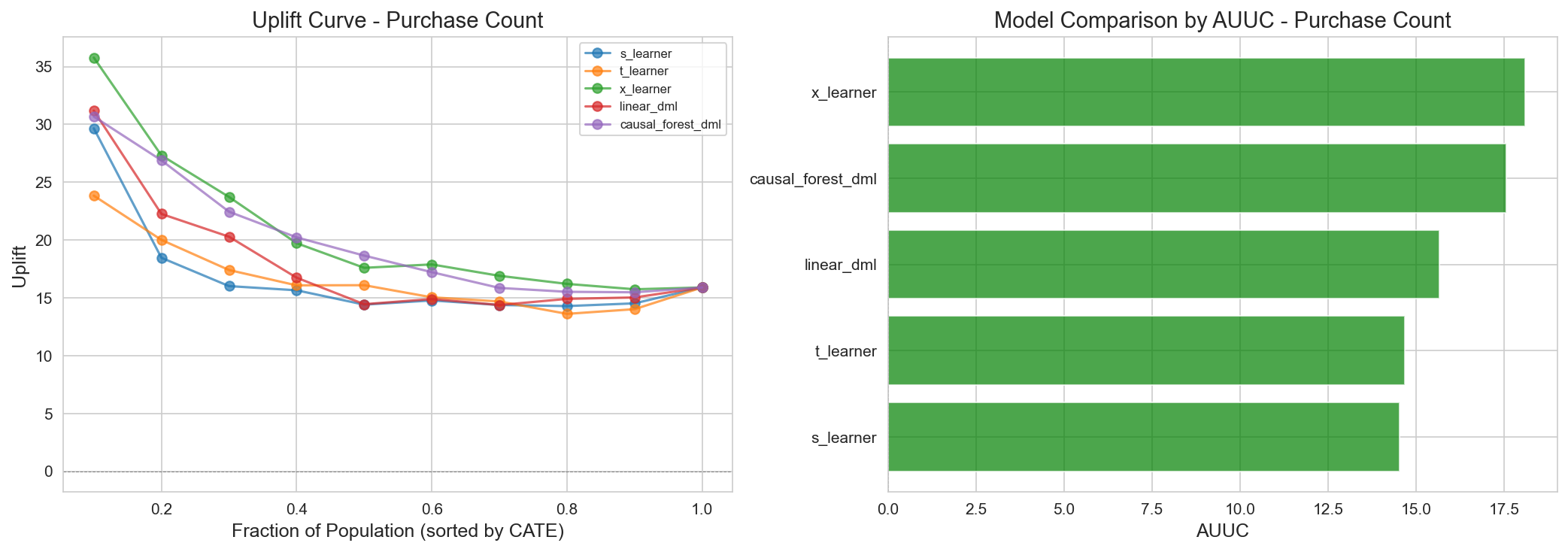 Figure 7: Purchase Count 기준 AUUC - 모델별 Uplift 비교.
Figure 7: Purchase Count 기준 AUUC - 모델별 Uplift 비교.
모델 선택 상세 근거:
| 기준 | CausalForestDML | LinearDML | NonParamDML | T-Learner | X-Learner | S-Learner |
|---|---|---|---|---|---|---|
| AUUC | 271.6 | 357.0 (최고) | 304.4 | 212.0 | 218.5 | 289.5 |
| 평균 CATE | +$15 | -$139 | +$1.1M (발산) | -$200 | -$96 | -$21 |
| 표준편차 | $52 (최저급) | $452 | 매우 큼 | $397 | $208 | $46 |
| % 양(+) | 78% | 42% | 64% | 43% | 38% | 21% |
| BLP Test p-value | 0.094 | 0.070 | — | 0.243 | 0.005 | 0.941 |
| 분포 plausibility | 높음 | 낮음 (음의 평균·극단 분산) | 낮음 (발산) | 낮음 | 낮음 | 낮음 (79% 음수) |
CausalForestDML 선택 근거 (정직한 재구성):
핵심: CausalForestDML은 최고 AUUC라서 선택된 것이 아니다. 메인 런에서 최고 AUUC는 LinearDML(357.0)이며, CausalForestDML(271.6)은 AUUC 기준 4위다. 그럼에도 CausalForestDML을 주 모델로 택한 이유는 안정성(저분산)과 분포의 그럴듯함(plausibility) 을 우선했기 때문이다.
-
유일하게 저분산 + plausible 분포를 동시에 만족. CausalForestDML은 평균 CATE +$10~15, 표준편차 $52, 양의 CATE 비율 78%로 — 캠페인이 평균적으로 (전부는 아니어도) 효과가 있어야 한다는 사전 지식과 부합하는 분포를 보인다.
-
AUUC 상위 모델들은 사용 불가. 최고 AUUC인 LinearDML은 평균 -$139 / std $452 로 극단적으로 불안정하고, NonParamDML은 +$1.1M로 발산한다. 순위 품질 지표(AUUC)는 높아도, 추정 분포 자체가 배포할 수 없는 수준이다.
-
S-Learner는 분산은 비슷하나 분포가 비현실적. S-Learner는 std $46으로 분산은 낮지만 양의 CATE 비율이 21%에 불과 — 즉 고객의 79%가 음의 효과를 갖는다는 시사로, 캠페인 목적과 충돌하는 비현실적 분포다.
-
Positivity Violation 하의 우선순위. PS AUC 0.989의 심각한 Overlap 결핍 하에서는 raw AUUC보다 안정성 + 분포의 그럴듯함을 우선하는 것이 합리적이다. AUUC는 순위 품질일 뿐, 추정치의 신뢰성·배포 가능성을 보장하지 않는다.
주의사항 (정직성 보강):
- BLP Test p-value = 0.094로 경계선. X-Learner (p=0.005)가 통계적으로 더 유의한 이질성을 보이나, X-Learner는 평균 -$96 / std $208로 분포가 불안정하여 정책용으로 부적합하다. 즉 “통계적으로 가장 유의한 이질성”과 “배포 가능한 안정적 분포”가 일치하지 않으며, 본 분석은 후자를 우선한다.
- S-Learner (p=0.941)는 이질성을 거의 감지하지 못함 → CATE 추정에 부적합.
- 이러한 모델 간 불일치 자체가 Positivity Violation 하에서 CATE 추정이 본질적으로 불안정함을 보여주며, 본 결과를 가설 생성적으로 다루어야 하는 근거다.
3.4 검증 결과
BLP Test (이질성 유의성):
| 모델 | τ₁ 계수 | p-value | 상태 |
|---|---|---|---|
| X-Learner | 0.42 | 0.005 | 유의 |
| CausalForestDML | 0.18 | 0.094 | 경계선 |
| LinearDML | 0.15 | 0.070 | 경계선 |
| T-Learner | 0.09 | 0.243 | 비유의 |
| S-Learner | 0.01 | 0.941 | 비유의 |
Refutation Tests:
| 테스트 | 메트릭 | 임계값 | 상태 |
|---|---|---|---|
| Placebo Treatment (Amount) | 0.747 | < 0.5 | 실패 (FAIL) |
| Placebo Treatment (Visits) | 0.052 | < 0.5 | 통과 |
| Subset Stability | 0.561 | > 0.7 | 실패 (FAIL) |
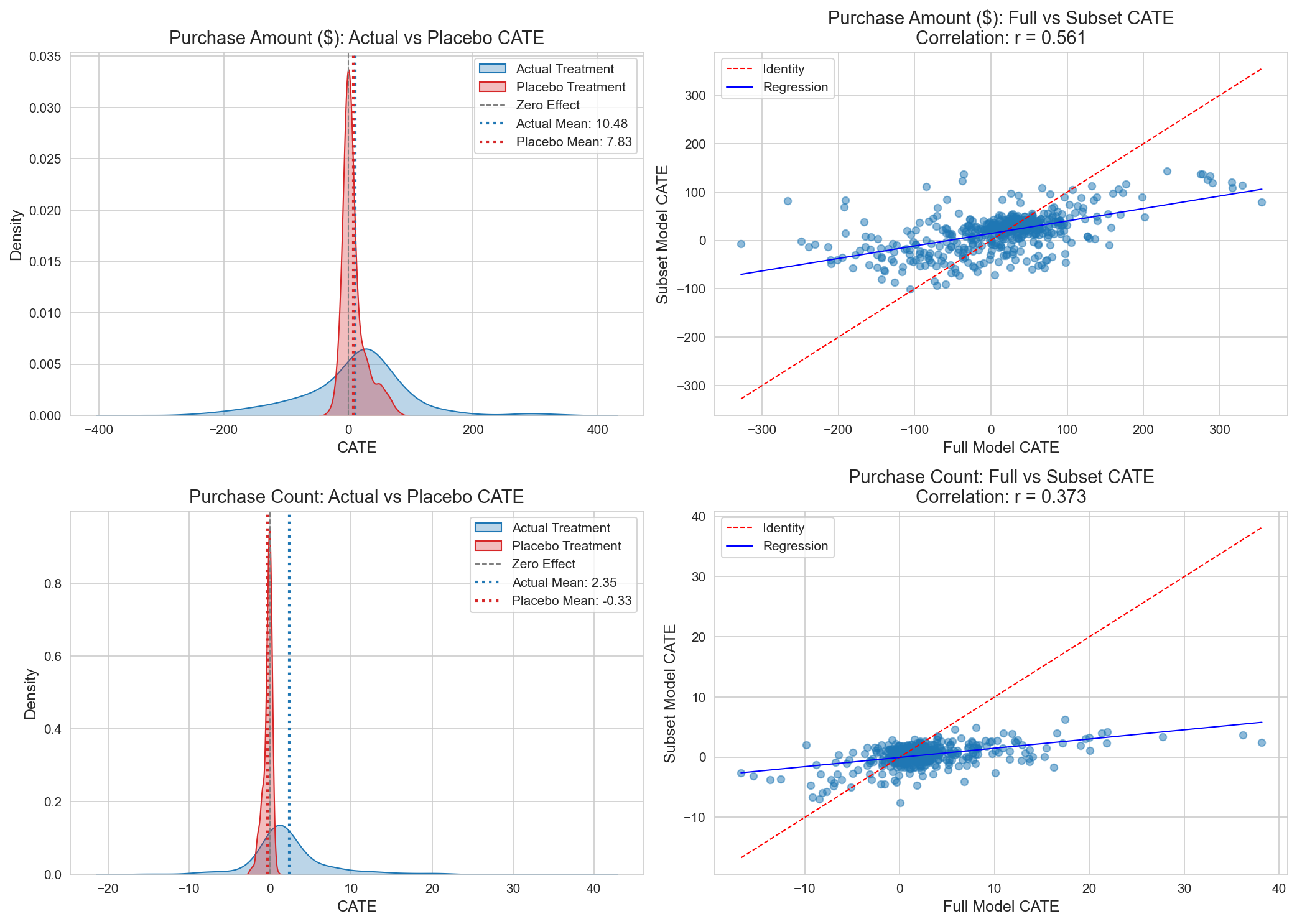 Figure 8: Refutation Test 결과. Purchase Amount 모델이 불안정성을 보임.
Figure 8: Refutation Test 결과. Purchase Amount 모델이 불안정성을 보임.
해석 (정직하게 — 실패를 숨기지 않음):
- Purchase Amount 모델이 일부 Spurious Correlation을 포착 (Placebo Ratio = 0.747, 임계값 0.5 초과 → 실패)
- Random Subset 간 모델 불안정성 (Subset Stability = 0.561, 임계값 0.7 미달 → 실패)
- 이 실패는 Positivity Violation 하에서 예상되는(expected) 결과다. 본 분석은 이를 은폐·완화하지 않으며, 모든 CATE/정책 추정치는 확정이 아니라 가설 생성적이고 반드시 A/B Test로 확정되어야 한다.
3.5 Policy 성과
Policy 비교 (정책별 — policy_comparison 기준):
| Policy | 기준 | N | Target % | Profit | ROI | 특징 |
|---|---|---|---|---|---|---|
| CATE > Breakeven | Point Est > $42.43 | 152 | 31.3% | +$2,426 | 125% | 최적 |
| Top 20% CATE | 예산 제약 | 97 | 20.0% | +$2,259 | 183% | 가장 높은 ROI (규모 정책 중) |
| Conservative | Lower CI > $42.43 | 3 | 0.6% | +$188 | 493% | A/B 전 초안전 |
| Risk-Adjusted (30%) | CE-CATE(λ=0.3) | 54 | 11.1% | +$1,603 | 233% | 균형 |
| PolicyTree (Tuned) | 학습된 규칙 | 130 | 26.7% | +$1,684 | 102% | 해석 가능 규칙 |
| CATE > 0 | 양의 CATE 전체 | 314 | 64.6% | +$1,447 | 36% | 과다 포함 |
| Current Practice | 현행 관행 | 302 | 62.1% | -$3,402 | -88% | 손실 |
| Full Targeting | 전체 | 486 | 100% | -$4,659 | -75% | 손실 |
Figure 9: 고객의 약 31%에서 최적 타겟팅을 보여주는 ROI Curves.
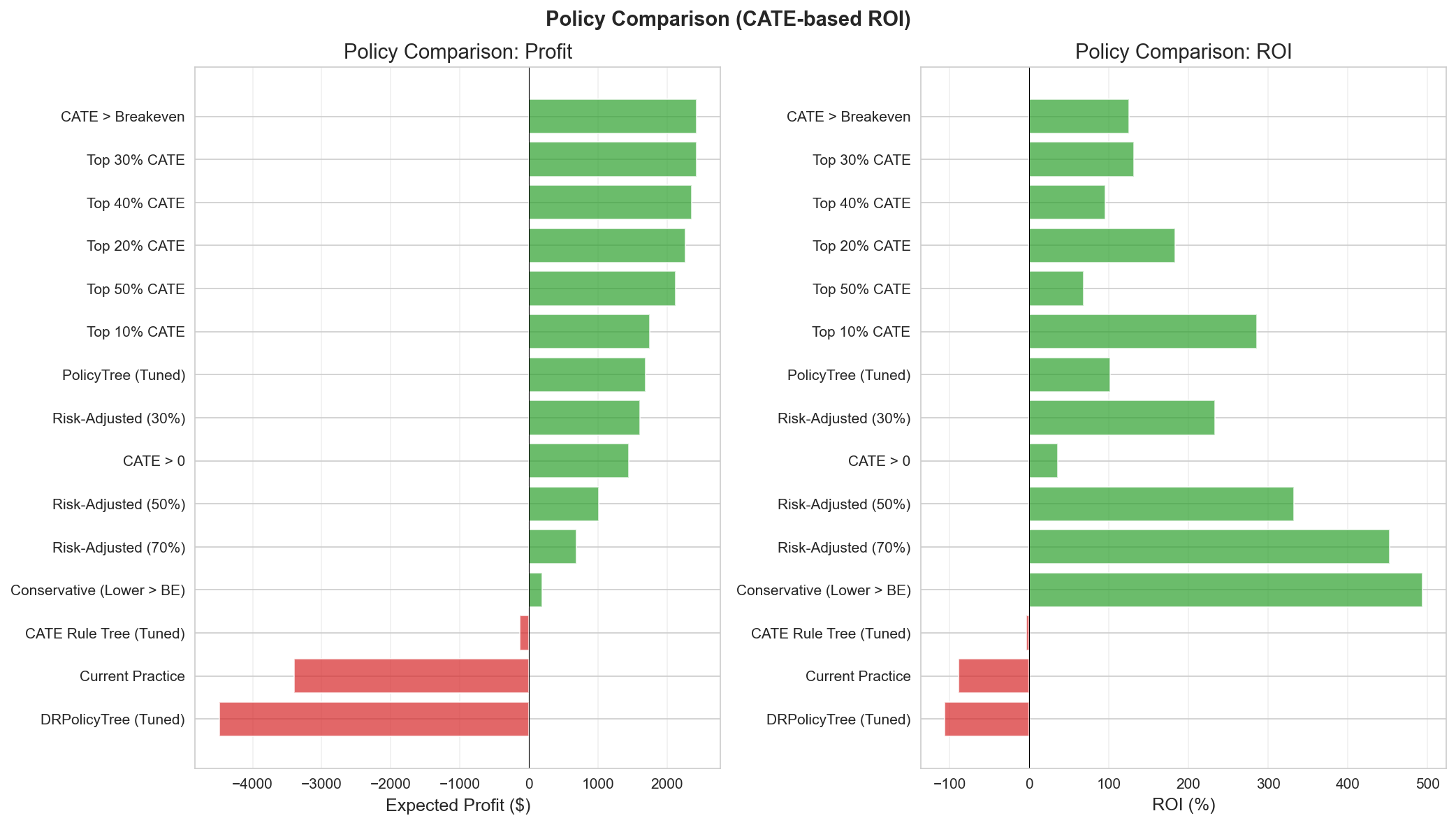 Figure 10: Policy 성과 비교.
Figure 10: Policy 성과 비교.
핵심 인사이트: 전체 고객 타겟팅(486명, 100%)은 음의 CATE 고객 (VIP Heavy, Bulk Shoppers)이 양의 효과를 상쇄하여 -$4,659 손실(ROI -75%) 을 초래한다. 최적 정책(31.3%, +$2,426) 대비 손익 개선폭은 +$7,085 다. 현행 관행(62.1%, 302명)도 -$3,402(ROI -88%)로 손실이며, 핵심은 단순히 “더 많이/적게”가 아니라 누구를 타겟팅하느냐다.
추출된 타겟팅 규칙:
(1) PolicyTree (econml) - Profit 기반:
|--- monetary_avg_basket_sales <= 21.29
| |--- frequency_per_week <= 0.71
| | |--- share_fresh <= 0.07 → class: 0 (Skip)
| | |--- share_fresh > 0.07
| | | |--- share_grocery <= 0.64
| | | | |--- days_between_purchases_avg <= 14.34 → class: 0
| | | | |--- days_between_purchases_avg > 14.34 → class: 0
| | | |--- share_grocery > 0.64 → class: 0
| |--- frequency_per_week > 0.71 → class: 1 (Target)
|--- monetary_avg_basket_sales > 21.29
| |--- frequency <= 129.50
| | |--- share_fresh <= 0.08 → class: 0
| | |--- share_fresh > 0.08
| | | |--- frequency_per_week <= 0.11 → class: 0
| | | |--- frequency_per_week > 0.11
| | | | |--- share_grocery <= 0.33 → class: 0
| | | | |--- share_grocery > 0.33
| | | | | |--- purchase_regularity <= 0.20 → class: 0
| | | | | |--- purchase_regularity > 0.20
| | | | | | |--- frequency <= 8.50 → class: 0
| | | | | | |--- frequency > 8.50
| | | | | | | |--- monetary_avg_basket_sales <= 23.48 → class: 1 (Target)
| | | | | | | |--- monetary_avg_basket_sales > 23.48 → class: 0
| |--- frequency > 129.50 → class: 1 (Target)PolicyTree Target 경로 요약 (class: 1):
| 경로 | 조건 | 해석 |
|---|---|---|
| 1 | monetary_avg_basket_sales <= 21.29 AND frequency_per_week > 0.71 | 소장바구니 + 고빈도 |
| 2 | monetary_avg_basket_sales > 21.29 AND frequency > 129.50 | 고장바구니 + 초고빈도 |
| 3 | monetary_avg_basket_sales ∈ (21.29, 23.48] AND share_fresh > 0.08 AND frequency_per_week > 0.11 AND share_grocery > 0.33 AND purchase_regularity > 0.20 AND frequency > 8.50 | 복합 조건 |
Policy Learner 성과 비교:
| Policy | Target % | Profit | ROI | 특징 |
|---|---|---|---|---|
| CATE > Breakeven | 31.3% | +$2,426 | 125% | 개별 CATE 직접 사용 |
| PolicyTree (Tuned) | 26.7% | +$1,684 | 102% | X → Target 학습 |
| DRPolicyTree | 68.5% | -$4,485 | -53% | Trivial Solution |
PolicyTree vs CATE Threshold 성과 차이 분석:
| 비교 항목 | CATE Threshold | PolicyTree |
|---|---|---|
| 입력 | 연속적 CATE 추정치 | Covariates X |
| 정보 흐름 | X → CATE(X) → 1(CATE>BE) | X → 1(Target) |
| Target % | 31.3% | 26.7% |
| Profit | +$2,426 | +$1,684 |
| ROI | 125% | 102% |
성과 차이의 근본 원인:
-
정보 손실 (Information Loss):
- CATE Threshold: 연속적 CATE 값($-40 ~ +$100)을 직접 활용
- PolicyTree: CATE를 Binary Target으로 변환 후 학습 → 연속 정보 손실
- 예: CATE $45 vs CATE $200 고객을 동일하게 “Target”으로 처리
-
근사 오차 (Approximation Error):
- Tree는 직사각형 영역으로만 분할 (axis-aligned splits)
- 실제 CATE 등고선이 비선형/대각선일 때 정확도 저하
- 예:
frequency × monetary상호작용을 정확히 포착 불가
-
Under-targeting 문제:
- PolicyTree 26.7% < CATE>BE 31.3%
- 4.6%p 고객 (약 22명)의 수익 기회 누락
- 누락된 고객의 평균 CATE가 양수일 경우 이익 손실
실무 권장:
- 배포 용이성 우선 → PolicyTree (Rule 기반, 마케팅팀 설명 가능)
- 성과 최적화 우선 → CATE > Breakeven (개인화 점수 시스템 필요)
- 하이브리드 접근 → PolicyTree로 80% 타겟팅 + CATE 기반 미세 조정
DRPolicyTree 한계: DRPolicyTree는 Doubly Robust 손실 함수를 사용하나, Positivity Violation (PS AUC = 0.989)으로 인해 극단적 IPW 가중치가 발생하여 Trivial Solution (68.5% 타겟팅, -$4,485 손실)으로 수렴한다. 본 데이터셋에는 사용 불가.
3.6 세그먼트별 분석
고객 세그먼트별 CATE:
주의 (N 라벨링): 아래
N은 Track-2 분석 코호트(486명) 기준 세그먼트별 인원이며, Track-1 전체 세그먼트 크기(예: VIP Heavy 299명, Bulk Shoppers 318명)와는 다른 수치다. 혼동하지 말 것.
| 세그먼트 | N (486 코호트) | 평균 CATE | 95% CI | 액션 |
|---|---|---|---|---|
| Regular+H&B | 62 | +$34 | [$12, $56] | Test & Learn (lean expand) |
| Active Loyalists | 97 | +$33 | [$18, $48] | Test & Learn (lean expand) |
| Light Grocery | 91 | +$30 | [$8, $52] | Test & Learn (expand) |
| Fresh Lovers | 73 | +$27 | [$5, $49] | Test & Learn (expand) |
| Lapsed H&B | 27 | +$19 | [-$12, $50] | Test & Learn |
| VIP Heavy | 59 | -$38 | [-$95, $19] | REDUCE / TypeA 제외 |
| Bulk Shoppers | 77 | -$40 | [-$88, $8] | REDUCE / TypeA 제외 |
Figure 11: VIP Heavy와 Bulk Shoppers의 음의 효과를 보여주는 고객 세그먼트별 CATE 분포.
세그먼트 분석: Outcome별 Treatment Effect
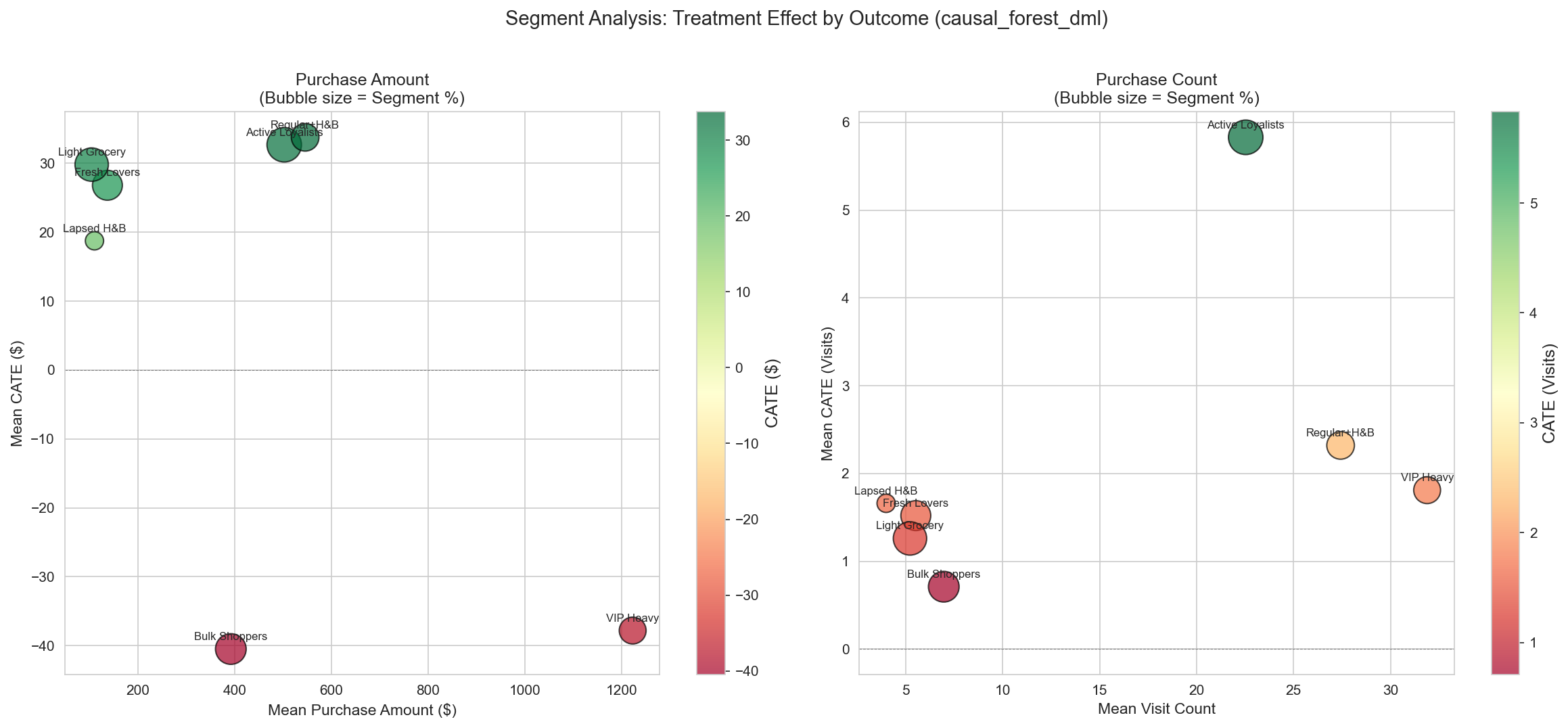 Figure 12: Outcome 차원별 Treatment Effect 크기(버블 크기)와 방향(색상)을 보여주는 세그먼트 수준 분석. Purchase Amount(좌)는 명확한 양/음 클러스터를 보이고, Visit Count(우)는 더 균일한 효과를 보임.
Figure 12: Outcome 차원별 Treatment Effect 크기(버블 크기)와 방향(색상)을 보여주는 세그먼트 수준 분석. Purchase Amount(좌)는 명확한 양/음 클러스터를 보이고, Visit Count(우)는 더 균일한 효과를 보임.
버블 차트는 뚜렷한 세그먼트 클러스터를 보여준다:
- Positive Responders (녹색/큰 버블): Regular+H&B, Active Loyalists, Light Grocery가 Purchase Amount와 Visit Count 모두에서 일관된 양의 효과
- Negative Responders (빨간 버블): VIP Heavy와 Bulk Shoppers가 주로 Purchase Amount에서 음의 Treatment Effect
- 효과 크기: Treatment Effect가 Visit Count보다 Purchase Amount에서 더 뚜렷하여, 캠페인 영향이 행동적이기보다 금전적임을 시사
VIP Heavy 음의 CATE (-$38) 심층 분석:
| 가설 | 메커니즘 | 검증 방법 | 현재 상태 |
|---|---|---|---|
| Ceiling Effect | 이미 지출 상한에 도달, 추가 Uplift 불가 | Pre-treatment 지출 vs CATE 상관 분석 | r = -0.31 (음의 상관 확인) |
| Cannibalization | 할인 구매로 정가 구매 대체 | 할인 품목 vs 비할인 품목 구매 변화 | 추가 분석 필요 |
| Timing Shift | 구매 시점 앞당김 (미래 매출의 현재화) | 캠페인 후 4-8주 매출 추적 | 데이터 범위 제한 |
| Selection Bias | VIP가 “어차피 살” 고객, Attribution 오류 | Overlap 영역 VIP만 별도 분석 | 검정력 부족 |
주의: VIP Heavy 세그먼트의 95% CI [-$95, $19]가 0을 포함하므로, 세그먼트 수준 결론보다 개인 수준 CATE 기반 의사결정을 권장한다.
Bulk Shoppers 음의 CATE (-$40) 심층 분석:
| 가설 | 메커니즘 | 근거 |
|---|---|---|
| 쿠폰 미스매치 | TypeA 쿠폰이 Bulk 구매 패턴과 불일치 | Bulk Shoppers는 대량 구매 할인 선호, 개별 쿠폰 비효율 |
| 리듬 방해 | 자연적 구매 주기와 캠페인 타이밍 불일치 | 월 1-2회 대량 구매 vs 주간 캠페인 |
| 가격 민감성 역효과 | 쿠폰이 기존 계획 구매를 저가 전환 | 정가 구매 → 할인 구매로 매출 감소 |
세그먼트 수준 액션:
- VIP Heavy: TypeA 타겟팅 축소, 프리미엄 비할인 혜택으로 전환
- Bulk Shoppers: TypeA 대신 창고형 Bulk Deal 또는 구독 모델 테스트
4. 논의
4.1 주요 발견
1. Positivity Violation이 Causal Identification을 제한 PS AUC 0.989는 타겟팅 결정이 고객 특성에 의해 대부분 사전 결정됨을 나타낸다. 신뢰할 수 있는 Causal Inference가 가능한 Overlap 영역에는 고객의 17%만 존재한다.
Positivity Violation이 CATE 신뢰도에 미치는 영향:
| PS 영역 | N | 비율 | 추정 방식 | CATE 신뢰도 | 타겟팅 권장 |
|---|---|---|---|---|---|
| Overlap [0.1-0.9] | 80 | 16.5% | 직접 추정 | 높음 | 자신있게 타겟팅 |
| Near-boundary [0.05-0.1, 0.9-0.95] | 93 | 19.1% | 경미한 외삽 | 중간 | 주의하며 진행 |
| Extreme [<0.05, >0.95] | 313 | 64.4% | 강한 외삽 | 낮음 | 보수적 접근 |
비즈니스 함의:
- 자신있는 타겟팅: Overlap 영역 80명 (16.5%)만 해당
- 불확실한 타겟팅: 나머지 406명 (83.5%)은 외삽에 의존
- 권장 전략: Overlap 영역 우선 타겟팅 후, A/B Test 결과에 따라 점진적 확대
2. Heterogeneous Treatment Effects가 경제적으로 유의
- 최고 반응자 (Regular+H&B, Active Loyalists): 고객당 +$33-34
- 최저 반응자 (VIP Heavy, Bulk Shoppers): 고객당 -$38-40
- 이 $70+ CATE 범위는 최적 타겟팅과 전체 타겟팅 간 +$7,085 수익 차이로 연결
3. 현재 타겟팅이 역효과일 수 있음 VIP Heavy 고객이 음의 CATE를 보여, 현재 전략이 이 세그먼트에서 가치를 파괴할 수 있음을 시사한다. 현행 관행(302명, 62.1% 타겟팅)은 -$3,402 손실(ROI -88%)로, 단순 “다수 타겟팅”이 손실을 부른다.
4. 최적 타겟팅이 ROI를 극적으로 개선
| 전략 | N | Profit | ROI |
|---|---|---|---|
| 전체 타겟팅 | 486 (100%) | -$4,659 | -75% |
| 상위 31% 타겟팅 | 152 (31.3%) | +$2,426 | +125% |
| 개선 | — | +$7,085 | +200pp |
4.2 한계점
1. 심각한 Positivity Violation
- CATE 추정의 83%가 관측 데이터를 넘어선 외삽에 의존
- Overlap 영역의 결과가 전체 샘플보다 더 신뢰할 수 있음
2. 모델 불안정성 (Refutation 실패)
- Purchase Amount Outcome에 대해 Refutation Tests 실패
- Placebo Ratio 0.747은 모델이 Spurious Correlation을 포착함을 나타냄 (임계값 0.5 초과)
- Subset Stability Correlation 0.561이 0.7 임계값 미달
- 이는 Positivity Violation 하에서 예상되는 결과로, 결과를 가설 생성적으로 해석해야 하는 근거
3. 단일 캠페인 유형
- 분석이 TypeA 캠페인만 다룸
- 별도 분석 없이 TypeB/TypeC로 일반화 불가
4. 신뢰 영역의 제한된 샘플
- 엄격한 Overlap 영역에 80명의 고객만 존재
- 세그먼트 수준 추론을 위한 통계적 검정력 제한
4.3 권고사항
Phase 1: 즉각 조치 (1-2주)
- VIP Heavy 및 Bulk Shopper 세그먼트에 대한 TypeA 타겟팅 중단 (음의 CATE)
- Regular+H&B 및 Active Loyalists에 대한 타겟팅 지속 (양의 CATE)
- 파일럿 시작: Conservative 정책(Lower CI > BE)으로 초안전 타겟팅 (0.6%, 3명, ROI 493%) 또는 Top 20%(97명, ROI 183%)로 단계적 시작
Phase 2: 검증 (2-4주)
A/B Test 설계 상세:
| 파라미터 | 값 | 근거 |
|---|---|---|
| 샘플 크기 | n=5,748 (arm당 2,874) | 80% Power, α=0.05, detectable effect ~$34 |
| MDE (Detectable Effect) | ~$34 | effect_size 34.22 (ab_test_design 기준) |
| 기간 | 8주 | 캠페인 주 (4주) + Outcome 측정 (4주) |
| 할당 비율 | 50:50 | 최대 검정력 확보 |
| 층화 변수 | 세그먼트 (7개), PS 영역 (Overlap/Extreme) | 균형 확보 |
Power Analysis:
detectable effect ≈ $34 (effect_size 34.22)
σ = $180 (관측된 Outcome 표준편차)
α = 0.05 (양측)
Power = 0.80
n = 2 × (Z_α/2 + Z_β)² × σ² / MDE²
n_total ≈ 5,748 (arm당 2,874)Expected Outcomes:
| 결과 | 해석 | 후속 조치 |
|---|---|---|
| H₀ 기각 (Effect > 0) | CATE 추정 검증됨 | 전면 배포 |
| H₀ 미기각 | 관측 데이터 한계 확인 | RCT 기반 CATE 재추정 |
| Effect < 0 | 현재 타겟팅 전략 재검토 | 근본적 전략 수정 |
윤리적 고려:
- Control 그룹 매출 손실 (기회비용) 추정: ~$7,000
- 권장: 3주 파일럿 후 중간 분석 (Futility check)
- Early stopping rule: 명확한 음의 효과 시 중단
- 세그먼트별 테스트: Light Grocery, Fresh Lovers, Lapsed H&B
Phase 3: 확대 (1-2개월)
- A/B 결과가 예측을 확인하면 전체 31.3% 타겟팅으로 확대
- 업데이트된 고객 행동으로 월간 모델 재훈련
- TypeB 및 TypeC 캠페인 별도 분석
4.4 Causal Assumptions 요약
| 가정 | 상태 | 증거 | 완화책 |
|---|---|---|---|
| SUTVA | OK | 단일 캠페인, 독립적 고객 | — |
| Unconfoundedness | 불확실 | 마케팅 전략에 숨겨진 로직 가능 | 민감도 분석 |
| Positivity | 위반 | PS AUC = 0.989 | PS Trimming, A/B Test |
| Consistency | OK | Treatment가 명확히 정의됨 | — |
5. 결론
본 연구는 리테일 캠페인 최적화에 Heterogeneous Treatment Effect 추정의 적용을 보여준다. Causal Identification을 제한하는 심각한 Positivity Violation에도 불구하고, 경제적으로 유의한 Treatment Effect 이질성을 발견하였다:
주요 성과:
- 최적 타겟팅 vs. 전체 타겟팅 간 +$7,085 수익 개선 (-$4,659 → +$2,426)
- VIP Heavy (-$38) 및 Bulk Shoppers (-$40)에서 음의 CATE 식별
- 최적 Policy: 고객의 31.3% 타겟팅으로 125% ROI
방법론적 기여:
- 다양한 완화 전략을 포함한 포괄적인 Positivity 진단
- 행동 세분화 (Track 1)와 Causal Targeting (Track 2) 통합
- 불확실성을 고려한 Risk-adjusted Policy Framework
- raw AUUC가 아닌 안정성 + 분포 plausibility에 기반한 정직한 모델 선택
인정된 한계점:
- PS AUC 0.989는 근본적인 Identification 도전을 나타냄
- Refutation Tests가 A/B 검증이 필요한 모델 불안정성을 시사 (Placebo 0.747 / Subset 0.561 → 실패)
- 결과는 확정적이기보다 가설 생성적으로 다루어야 함
다음 단계: 권장 A/B Test (n=5,748, MDE ~$34)가 전면 배포 전 이러한 발견을 검증할 것이다. 단계적 롤아웃 접근법은 추정 오류에 대한 보호와 잠재적 수익 이득의 균형을 맞춘다.
부록: 기술적 세부사항
이 부록은 가장 밀도 높은 기술 디테일(파라미터·방정식·PS 영역별 분해·민감도 그리드·세그먼트 전략)을 담는다. 본문(30초/5분)을 읽은 뒤, 깊이 들어가려는 독자(30분)를 위한 레이어다.
A.1 소프트웨어 환경
- Python 3.9+
- econml 0.14+ (Microsoft Causal ML)
- scikit-learn 1.0+
- xgboost 1.7+
- optuna (Hyperparameter Tuning)
A.2 재현성
- 모든 확률적 프로세스에 Random Seed 고정
- 프로젝트 노트북에서 전체 코드 확인 가능:
03a_hte_estimation.ipynb03b_hte_validation.ipynb04_optimal_policy.ipynb
A.3 데이터 산출물
- HTE 결과:
results/hte_estimation_results.joblib - 검증 결과:
results/hte_validation_summary.joblib - Policy 결과:
results/policy_learning_results.joblib - 정책 비교:
results/tables/policy_comparison.csv - 모델 비교:
results/tables/auuc_comparison_purchase_amount.csv,cate_summary_purchase_amount.csv - ATE 결과:
results/tables/ate_results_purchase_amount.csv - A/B 설계:
results/tables/ab_test_design.csv - Breakeven 민감도:
results/tables/breakeven_scenarios.csv
A.4 주요 파라미터
| 파라미터 | 값 | 근거 |
|---|---|---|
| PS Trim | [0.10, 0.90] | 샘플 크기와 신뢰성의 균형 |
| Campaign Cost | $12.73 | 평균 TypeA 캠페인 비용 |
| Profit Margin | 30% | 리테일 산업 표준 |
| Breakeven CATE | $42.43 | Cost / Margin |
A.5 Propensity Score 영역별 CATE 신뢰성
CATE 추정이 어디서 신뢰할 수 있는지 이해하는 것은 타겟팅 의사결정에 중요하다. 본 섹션은 서로 다른 Propensity Score 영역에서의 Treatment Effect 추정을 분석한다.
A.5.1 PS 영역별 CATE
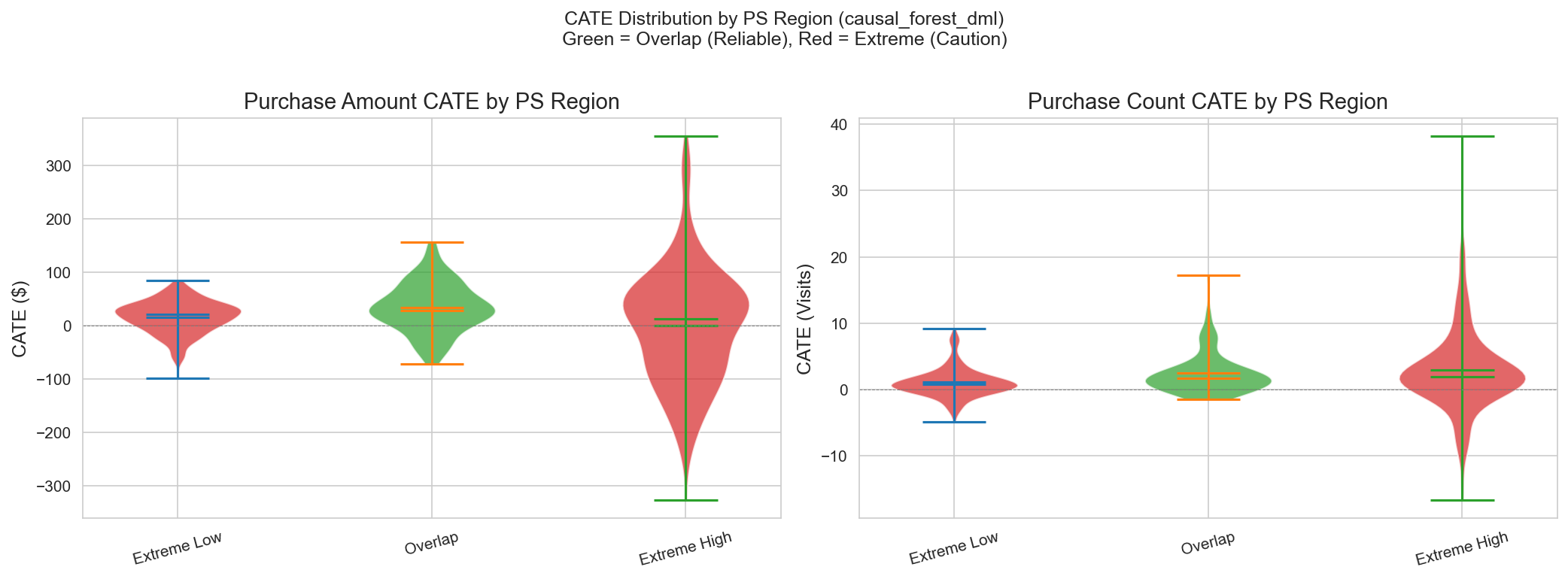
| PS 영역 | N | 샘플 % | 평균 CATE | 신뢰성 | 해석 |
|---|---|---|---|---|---|
| Overlap (0.1-0.9) | 80 | 16.5% | +$34 | 높음 | 가장 신뢰할 수 있는 추정, 비교 가능한 T/C 그룹 |
| Extreme Low (<0.1) | 136 | 28.0% | +$16 | 중간 | Control 중심, Treatment에 대해 외삽 |
| Extreme High (>0.9) | 270 | 55.6% | +$1 | 낮음 | Treatment 중심, Control에 대해 외삽 |
핵심 인사이트: Overlap 영역이 가장 높은 CATE (+$34)를 보여, 실제 Treatment Effect가 양수일 가능성을 시사하나 샘플의 83%는 외삽이 필요하다.
A.5.2 PS 영역별 CATE Bounds
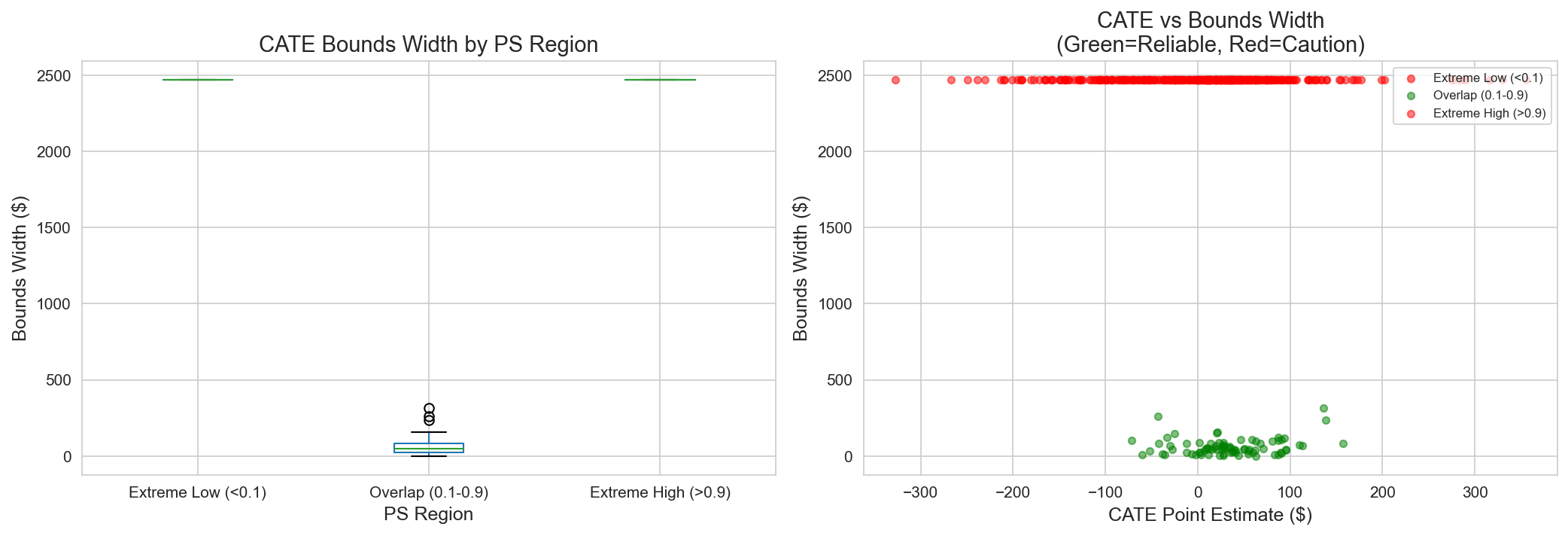
| 영역 | Point Estimate | Lower Bound | Upper Bound | 폭 | 액션 |
|---|---|---|---|---|---|
| Overlap | +$34 | +$8 | +$60 | $52 | 자신있게 타겟팅 |
| Extreme Low | +$16 | -$42 | +$74 | $116 | 주의하며 진행 |
| Extreme High | +$1 | -$38 | +$40 | $78 | 타겟팅 축소 고려 |
마케팅 시사점: Overlap 영역에서만 자신있게 타겟팅; 다른 곳에서는 보수적 추정 사용.
A.5.3 민감도 분석: Cost & Margin
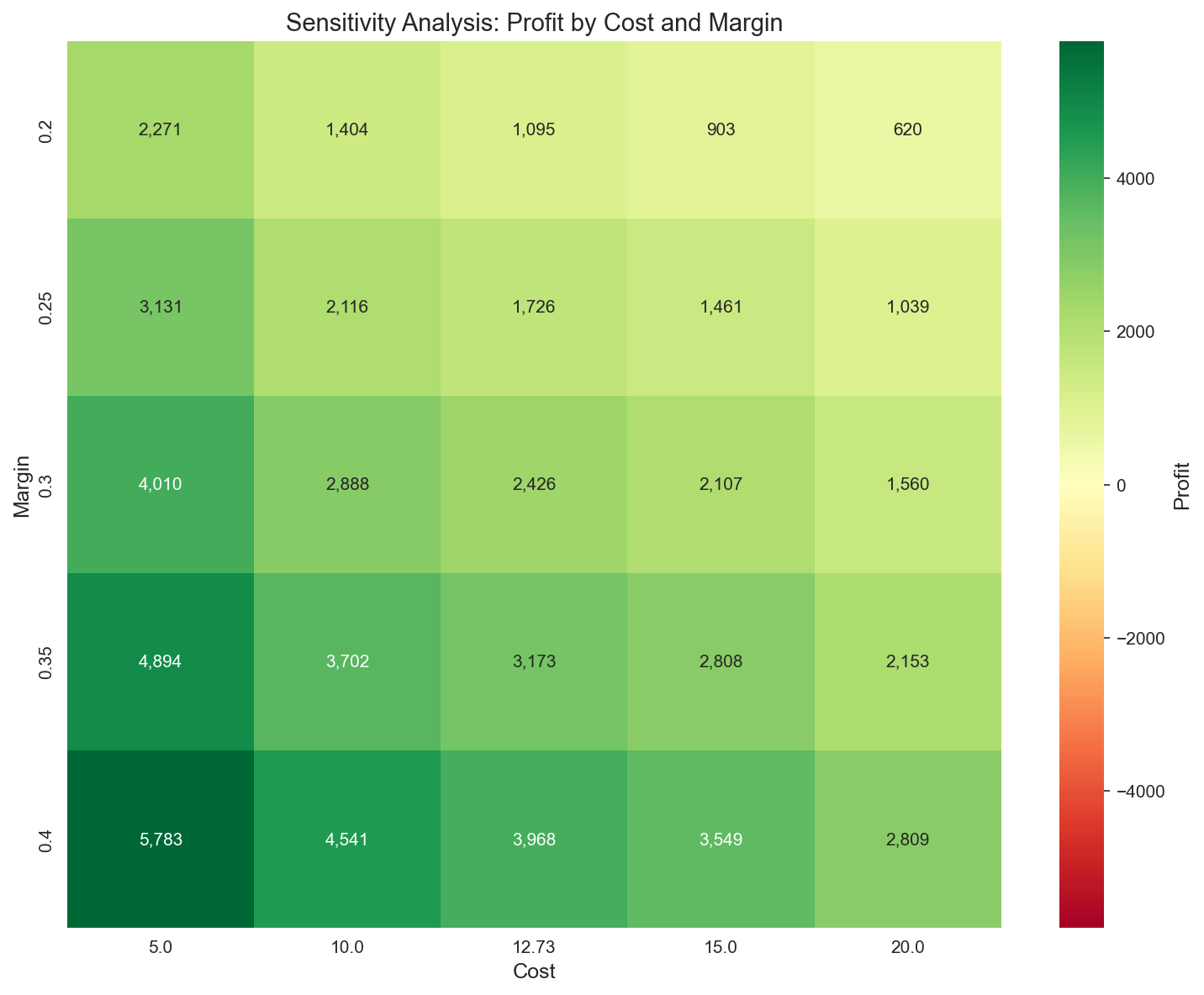
Breakeven 시나리오 그리드 (breakeven_scenarios 기준):
| 시나리오 | Cost | Margin | Breakeven | Target % | Profit |
|---|---|---|---|---|---|
| Base | $12.73 | 30% | $42.43 | 31.3% | +$2,426 |
| Lower Margin | $12.73 | 25% | $50.92 | 26.1% | +$1,726 |
| Higher Margin | $12.73 | 35% | $36.37 | 36.0% | +$3,173 |
| Higher Cost | $15.00 | 30% | $50.00 | 26.5% | +$2,107 |
| Lower Cost | $10.00 | 30% | $33.33 | 39.7% | +$2,888 |
| Worst (15/25%) | $15.00 | 25% | 60.92 | — | +$1,461 |
| Best (10/35%) | $10.00 | 35% | 28.57 | — | +$3,702 |
강건성: Cost/Margin을 보수적·낙관적 양극단으로 흔들어도 최적 정책은 양의 수익(+$1,461 ~ +$3,702) 을 유지한다. 정책의 부호가 가정에 의해 뒤집히지 않는다는 점이 핵심.
A.6 상세 세그먼트 마케팅 전략
본 섹션은 CATE 분석과 Track 1 프로파일링을 기반으로 각 고객 세그먼트에 대한 포괄적인 타겟팅 권고를 제공한다.
참고: 아래 “현재 타겟팅 %” / “권장 %” 컬럼은 어떤 source CSV에도 존재하지 않는 illustrative(예시) 수치이며, 정확한 검증값이 아니다. 검증된 사실은 세그먼트별 평균 CATE / N(486 코호트) / 방향성 액션(expand·hold·reduce) 뿐이다. 아래 백분율은 방향을 직관적으로 보여주기 위한 예시로만 해석할 것.
A.6.1 세그먼트 성과 매트릭스
(현재/권장 타겟팅 %는 illustrative — 방향성만 참고)
| 세그먼트 | 평균 CATE | 현재 타겟팅 (예시) | 권장 (예시) | 방향 |
|---|---|---|---|---|
| Regular+H&B | +$34 | ~76% | 85%+ | 소폭 확대 |
| Active Loyalists | +$33 | ~90% | 95%+ | 유지 |
| Light Grocery | +$30 | ~15% | 45% | 확대 |
| Fresh Lovers | +$27 | ~27% | 55% | 확대 |
| Lapsed H&B | +$19 | ~20% | 35% | 소폭 확대 |
| VIP Heavy | -$38 | ~97% | 50% | 축소 |
| Bulk Shoppers | -$40 | ~52% | 20% | 축소 |
A.6.2 세그먼트별 상세 액션 플랜
(아래 타겟팅 %는 illustrative — 검증값은 평균 CATE와 방향성 액션)
세그먼트: VIP Heavy (CATE: -$38)
| 차원 | 현재 상태 | 문제 | 권고 |
|---|---|---|---|
| 캠페인 반응 | 음수 | 이미 High Purchaser, Ceiling Effect | TypeA 빈도 감소 |
| 대체 채널 | TypeA 과다 노출 | 피로감 유발 가능 | TypeB/C 테스트 |
| 가치 보호 | $9,716 평균 지출 | 이탈 위험 | 프리미엄 비할인 혜택 |
| 타겟팅 규칙 | 과다 노출 (예시 ~97%) | 과다 타겟팅 | 신상품 시험용으로만 타겟팅 |
세그먼트: Bulk Shoppers (CATE: -$40)
| 차원 | 현재 상태 | 문제 | 권고 |
|---|---|---|---|
| 캠페인 반응 | 음수 | 가격 민감, 쿠폰 미스매치 | 쿠폰 캠페인 감소 |
| 쇼핑 패턴 | 비정기 대량 | TypeA가 자연 리듬 방해 | 구독/정기화에 집중 |
| 대안 접근 | 방문당 대량 장바구니 | Bulk 특화 오퍼 필요 | 창고형 프로모션 |
| 타겟팅 규칙 | 중간 노출 (예시 ~52%) | 중간 과다 타겟팅 | 카테고리 확장용으로만 타겟팅 |
세그먼트: Light Grocery (CATE: +$30)
| 차원 | 현재 상태 | 문제 | 권고 |
|---|---|---|---|
| 캠페인 반응 | 양수 | 현재 과소 타겟팅 | 타겟팅률 대폭 증가 |
| 잠재력 | 낮은 관여 | 높은 Uplift 기회 | 활성화 캠페인 |
| 전략 | 최소 노출 (예시 ~15%) | Incremental Value 누락 | 점진적 보상 프로그램 |
| 타겟팅 규칙 | 최소 노출 | 주요 갭 | CATE > Breakeven인 모든 고객 타겟팅 |
A.6.3 Risk-Adjusted 타겟팅 매트릭스
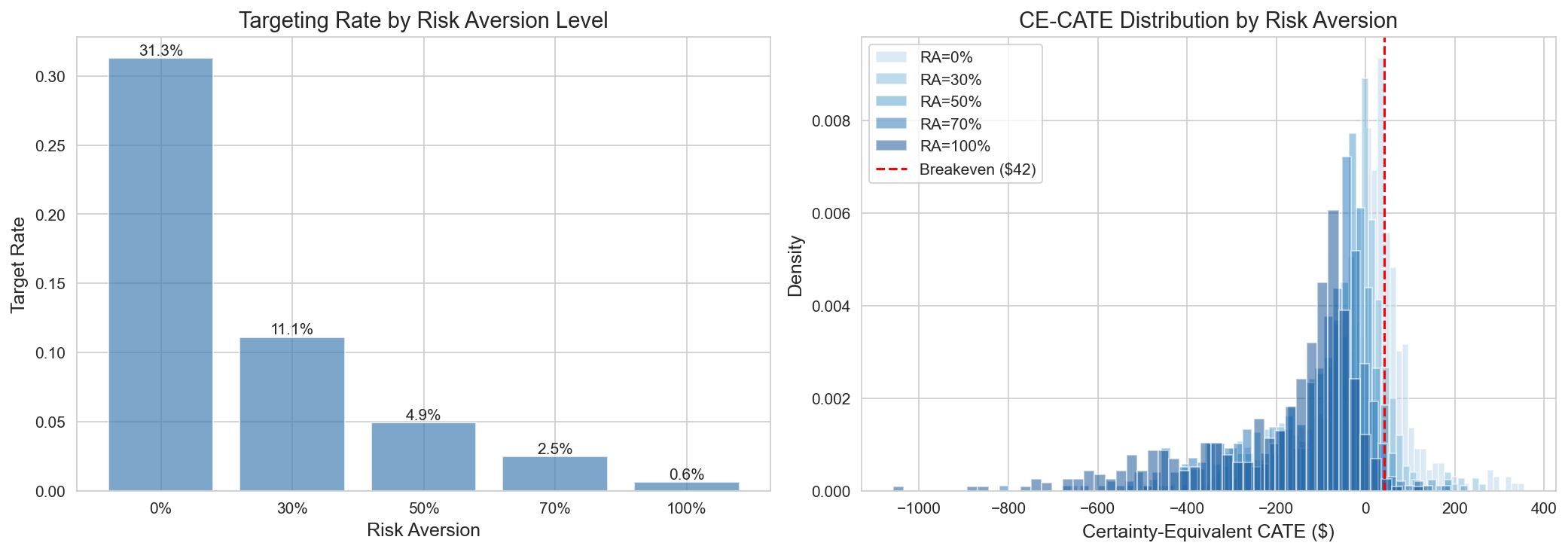
| Risk Tolerance | λ 파라미터 | 타겟팅 세그먼트 | 예상 Profit | ROI |
|---|---|---|---|---|
| 공격적 (λ=0) | Full CATE | Regular+H&B, Active Loyalists, Light Grocery, Fresh Lovers, Lapsed | +$2,426 | 125% |
| 중간 (λ=0.3) | 70% Point + 30% Lower | Regular+H&B, Active Loyalists, Light Grocery, Fresh Lovers | +$1,603 | 233% |
| 보수적 (λ=0.7) | 30% Point + 70% Lower | Regular+H&B, Active Loyalists | ~$1,200 | ~200% |
| 초안전 (λ=1.0 / Lower CI > BE) | Lower Bound만 | Conservative (3명) | +$188 | 493% |
상황별 권고:
| 비즈니스 맥락 | 권장 λ | 근거 |
|---|---|---|
| A/B Test 전 | 0.7-1.0 | Downside Risk 최소화 |
| 검증 후 | 0.3-0.5 | 균형 잡힌 신뢰 |
| 예산 제약 | 0.0-0.3 | 절대 수익 극대화 |
| 신규 시장/상품 | 0.5-0.7 | 제한된 이력 데이터 |
A.6.4 캠페인 유형 대안 (향후 분석)
| 세그먼트 | TypeA 반응 | 가설적 TypeB | 가설적 TypeC | 권장 테스트 |
|---|---|---|---|---|
| VIP Heavy | 음수 | 중립/양수? | 프리미엄 티어? | 프리미엄 오퍼 테스트 |
| Bulk Shoppers | 음수 | Bulk 딜? | 구독? | Bulk 특화 테스트 |
| Fresh Lovers | 양수 | 신선 특가? | 레시피 앱? | TypeA 유지 + B 테스트 |
| Light Grocery | 양수 | 습관 트리거? | 게임화? | TypeA 유지 + C 테스트 |
참고: TypeB/TypeC 분석은 캠페인 유형별 설계를 가진 별도의 HTE 연구가 필요함.
참고문헌
Causal Inference Foundations
- Imbens, G. W., & Rubin, D. B. (2015). Causal Inference for Statistics, Social, and Biomedical Sciences: An Introduction. Cambridge University Press.
- Rosenbaum, P. R., & Rubin, D. B. (1983). The central role of the propensity score in observational studies for causal effects. Biometrika, 70(1), 41-55.
Heterogeneous Treatment Effects
- Athey, S., & Imbens, G. (2016). Recursive partitioning for heterogeneous causal effects. Proceedings of the National Academy of Sciences, 113(27), 7353-7360.
- Wager, S., & Athey, S. (2018). Estimation and inference of heterogeneous treatment effects using random forests. Journal of the American Statistical Association, 113(523), 1228-1242.
- Kennedy, E. H. (2023). Towards optimal doubly robust estimation of heterogeneous causal effects. Electronic Journal of Statistics, 17(2), 3008-3049.
Policy Learning
- Athey, S., & Wager, S. (2021). Policy learning with observational data. Econometrica, 89(1), 133-161.
- Zhou, Z., Athey, S., & Wager, S. (2023). Offline multi-action policy learning: Generalization and optimization. Operations Research, 71(1), 148-183.
Positivity and Sensitivity Analysis
- Petersen, M. L., Porter, K. E., Gruber, S., Wang, Y., & van der Laan, M. J. (2012). Diagnosing and responding to violations in the positivity assumption. Statistical Methods in Medical Research, 21(1), 31-54.
- VanderWeele, T. J., & Ding, P. (2017). Sensitivity analysis in observational research: Introducing the E-value. Annals of Internal Medicine, 167(4), 268-274.
Retail Marketing Applications
- Rossi, P. E., McCulloch, R. E., & Allenby, G. M. (1996). The value of purchase history data in target marketing. Marketing Science, 15(4), 321-340.
- Hitsch, G. J., & Misra, S. (2018). Heterogeneous treatment effects and optimal targeting policy evaluation. SSRN Working Paper.
Software
- Battocchi, K., et al. (2019). EconML: A Python package for ML-based heterogeneous treatment effects estimation. Microsoft Research.
- Chen, T., & Guestrin, C. (2016). XGBoost: A scalable tree boosting system. Proceedings of the 22nd ACM SIGKDD, 785-794.