인과 기반 멀티터치 어트리뷰션
단일 Inhomogeneous Poisson Process 위에 Incremental·Shapley 채널 기여도와 path-level 분해를 통합해, 채널 예산·여정 설계·모집단 인과효과를 하나의 효율성 항등식으로 답한 시뮬레이션 연구(18-method 벤치마크, ground-truth MAE 0.016
⏱️ TL;DR (30초)
- 무엇 — Shender et al.(2023)의 생존분석 백본인 Inhomogeneous Poisson Process(IPP) 위에 Du et al.(2019)의 Incremental Shapley를 하나의 적합 모델로 합쳤다. 여기에 여정 단위로 분해하는 path-level Incremental Shapley와 두 estimand를 다루는 Conditional vs Marginal G-computation까지 얹은 인과 기반 MTA다.
- 왜 — 기존 MTA는 상관에 답한다(Last Click, Shapley). 이 방법은 A/B 테스트 없이 관측 데이터만으로 인과(“이 채널이 없었다면?”)를 묻고, 채널 효과·시간 감쇠·시너지·incremental lift를 분리해낸다.
- 무엇을 보였나 — 시뮬레이션 ground truth 기준으로 18개 방법 중 채널 기여도 오차가 가장 낮았고(MAE 0.016, 1위), 예산 배분도 2위(MAE 0.019) 였다. 정확도 높은 방법치고는 드물게 부트스트랩 변동성도 낮다(mean CV 0.13). 그리고 채널·여정·모집단 세 관점이 하나의 효율성 항등식으로 상대오차 0.00%까지 일치한다.
 단일 Inhomogeneous Poisson Process(백본) 위에 credit 층과 path 층을 얹으면, 채널 예산·여정 설계·모집단 효과라는 세 관점이 하나의 효율성 항등식(상대오차 0.00%) 으로 묶인다. 이것이 이 방법론의 핵심 주장이다.
단일 Inhomogeneous Poisson Process(백본) 위에 credit 층과 path 층을 얹으면, 채널 예산·여정 설계·모집단 효과라는 세 관점이 하나의 효율성 항등식(상대오차 0.00%) 으로 묶인다. 이것이 이 방법론의 핵심 주장이다.
🎯 핵심 결과 한눈에
| 지표 | 값 | 비고 |
|---|---|---|
| 채널 기여도 오차 | MAE 0.016 | 18개 방법 중 1위 (ground truth 대비) |
| 예산배분 정확도 | MAE 0.019 | 2위 (1위 Du Incremental Shapley 0.013) |
| 효율성 항등식 | 상대오차 0.00% | 채널·여정·모집단 세 관점 일치 |
| 부트스트랩 안정성 | mean CV 0.13 | 동급 Incremental·Total Shapley는 0.60·0.99로 불안정 |
| 순위 일치도 | Kendall τ = 0.905 | ground truth 순위와 robust 정합 |
| 두 estimand | Conditional MAE 0.012 · Marginal MAE 0.020 | 사후 audit / 전향 A/B 정렬 |
| 데이터 | 100K users · 7 channels · ~2.3% 전환 | 합성 DGP (ground truth 보유) |
모든 수치는 시뮬레이션 ground truth 기준이다. 합성 DGP에서 나온 illustrative 값이며, 실데이터에는 ground truth가 없다(§한계 참조).
🔬 핵심 실험 두 가지
이 방법론이 내놓는 두 산출물이자, 프로젝트에서 가장 중요하게 본 두 실험이다.
① Incremental vs Total — 왜 ‘incremental’이 필수인가. base 전환율을 ~3%에서 ~20%까지 올리며 두 ground truth와 세 연산자를 한 그림에 겹쳤다. 두 ground truth는 묻는 질문이 다르다. GT_A는 “전환에 누가 있었나” 를 보는 사후 정산(conditional)의 진실이고, GT_B는 “이 채널이 없었다면 무엇을 잃나” 를 보는, A/B 테스트가 재는 incremental(marginal)의 진실이다. 둘은 채널 순위는 같지만 크기가 갈린다(Paid Search는 GT_A 0.315 > GT_B 0.299, Display는 반대로 GT_B 0.084 > GT_A 0.061). 세 연산자(Incremental·Total·BackElim) 중 Total Shapley는 “광고가 없어도 일어났을” baseline까지 크레딧에 넣기 때문에, base rate가 오르면 upper-funnel(Display·Social)을 0으로 무너뜨리고 Paid Search를 두 진실보다도 과대평가한다. 반면 Incremental Shapley는 baseline을 빼서 두 진실 사이 밴드 안에 머문다. base rate가 아무리 높아져도 흔들리지 않는다.
구독 갱신이나 브랜드처럼 자연 전환이 높은 비즈니스에서 Total Shapley를 쓰면, 진짜 가치 동력이 아닌 Paid Search에 예산을 과투자하게 된다. incremental이 선택이 아니라 필수인 이유다.
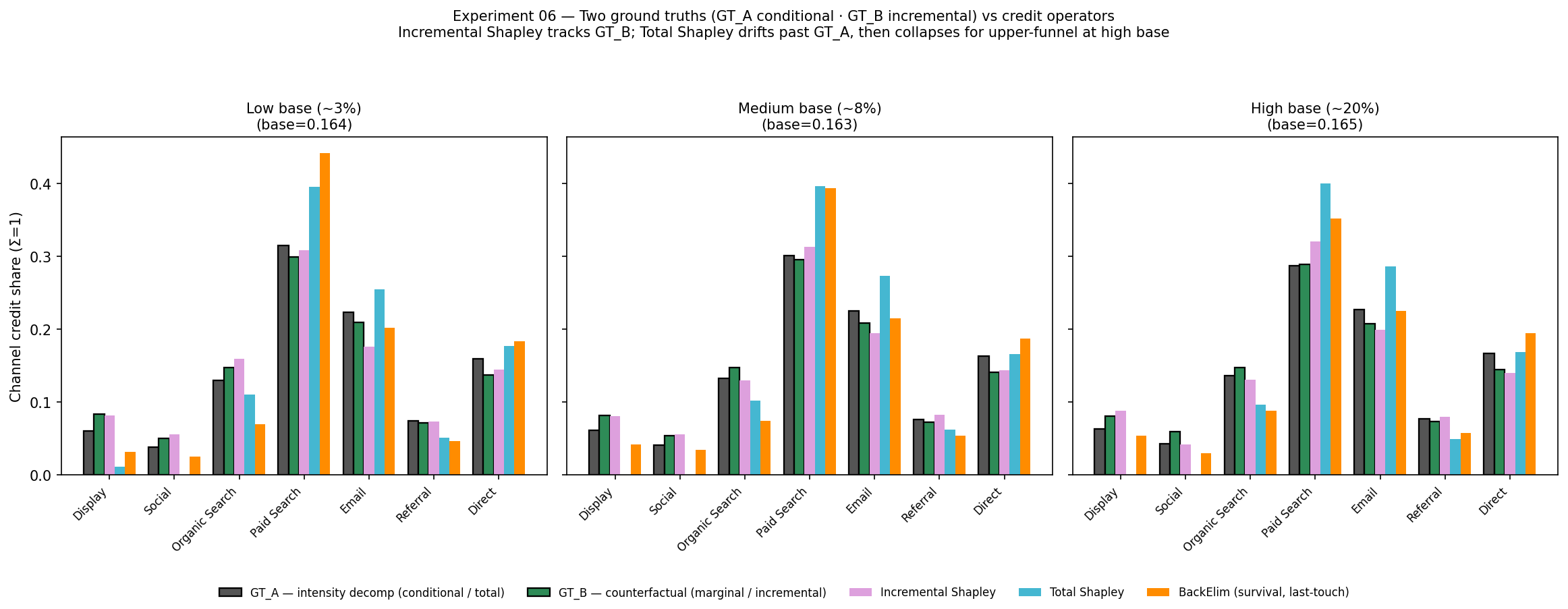 막대 다섯 개 — 두 ground truth(GT_A 회색·conditional, GT_B 초록·incremental, 둘 다 검은 테두리)와 세 연산자다. Incremental(분홍)은 두 진실 밴드 안에 머물지만, Total(하늘)은 둘 모두에서 벗어난다. Paid Search를 과대평가하고(high base 0.400 vs GT ~0.29) Display·Social은 0으로 무너뜨린다(GT 0.080·0.059인데 Total은 0.00). BackElim(주황)은 last-touch에 크레딧이 쏠린다. 진짜 incremental credit이 왜 필요한지 보여주는 그림이다.
막대 다섯 개 — 두 ground truth(GT_A 회색·conditional, GT_B 초록·incremental, 둘 다 검은 테두리)와 세 연산자다. Incremental(분홍)은 두 진실 밴드 안에 머물지만, Total(하늘)은 둘 모두에서 벗어난다. Paid Search를 과대평가하고(high base 0.400 vs GT ~0.29) Display·Social은 0으로 무너뜨린다(GT 0.080·0.059인데 Total은 0.00). BackElim(주황)은 last-touch에 크레딧이 쏠린다. 진짜 incremental credit이 왜 필요한지 보여주는 그림이다.
② Multi-path — 채널이 아니라 ‘여정’을 평가.
같은 IPP를 채널이 아니라 여정 템플릿(ordered channel tuple) 단위로 분해한다. 1,786개 여정 가운데 count ≥ 5를 넘는 35개 robust 템플릿(전환자의 15.5%)만 남기면, 재현 가능한 캠페인 후보가 추려진다. total contribution 상위(Email→Paid Search 등)는 “지금 매출을 떠받치는” 여정이고, mean Δ 상위(드문 3-step)는 “의도적으로 설계해볼” 후보다.
“어느 채널에 돈을 쓸까”(예산)와 “어떤 여정을 키울까”(캠페인 설계)는 보통 따로 분석한다. 하지만 여기서는 같은 효율성 항등식에서 함께 나오므로, 두 결정이 서로 어긋나지 않는다.
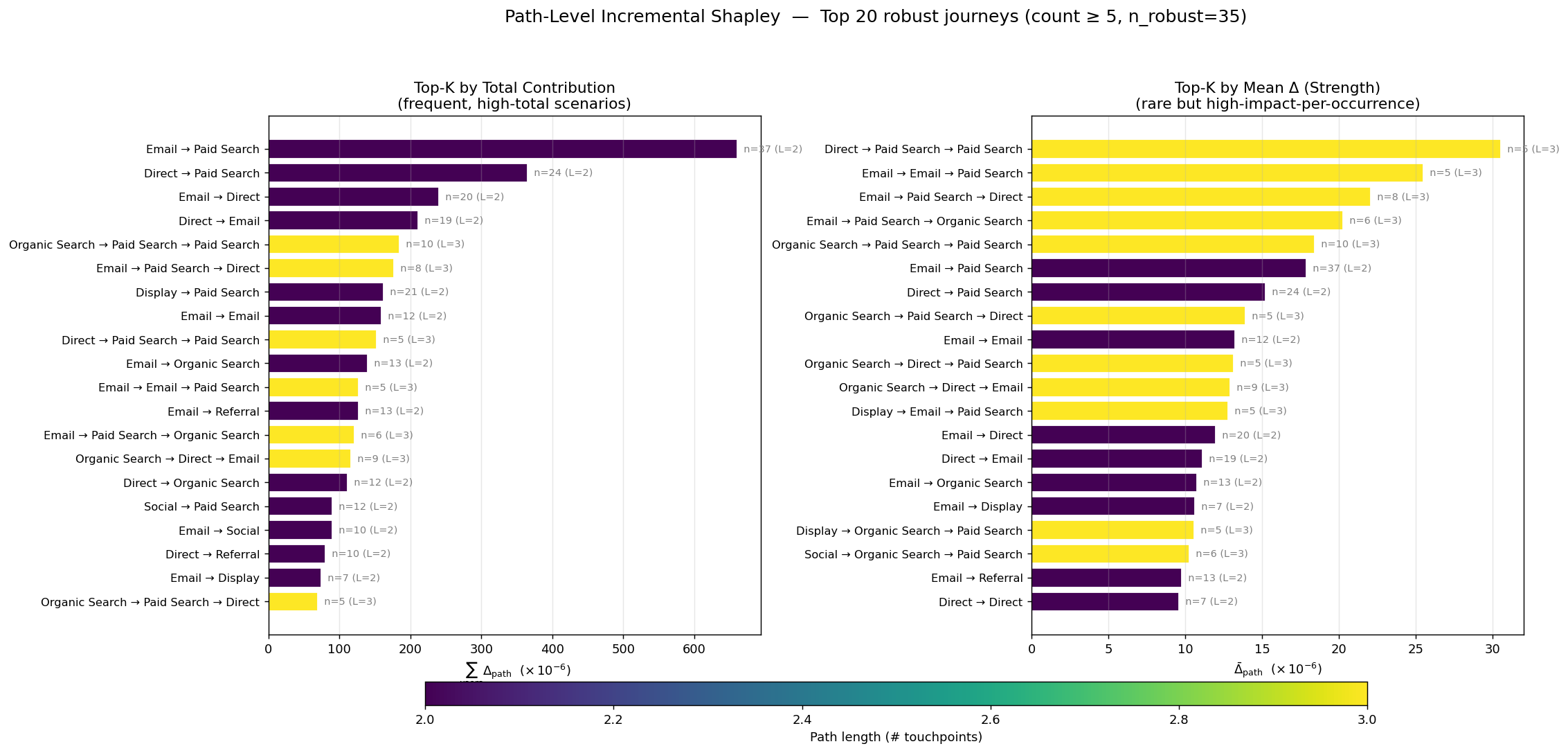 path-level Incremental Shapley로 순위를 매긴 35개 robust 여정. (좌) total contribution은 지금 매출을 떠받치는 짧고 빈번한 2-step, (우) mean Δ는 드물지만 한 명당 임팩트가 큰 3-step 설계 후보다. 색은 여정 길이를 나타낸다.
path-level Incremental Shapley로 순위를 매긴 35개 robust 여정. (좌) total contribution은 지금 매출을 떠받치는 짧고 빈번한 2-step, (우) mean Δ는 드물지만 한 명당 임팩트가 큰 3-step 설계 후보다. 색은 여정 길이를 나타낸다.
🧱 방법 — 단일 IPP 위 3층
이 방법론의 척추는 하나의 fitted Inhomogeneous Poisson Process(IPP) 위에 세 층을 쌓은 구조다. 모델은 한 번만 적합하고, 그 위에서 채널 기여도·여정 분해·모집단 효과를 모두 같은 게임으로 끌어낸다.
- 백본 (IPP) — 마케팅 여정을 time-to-event 데이터로 보고, 시간에 따라 변하는 intensity 를 갖는 Poisson process로 모델링한다. 각 터치를 시간 구간으로 쪼개 interval-split Poisson GLM(offset = log Δt)으로 적합하면 우측 절단(right-censoring)도 자연스럽게 처리된다. 채널별 5-bin 감쇠 곡선은 데이터에서 학습하는데, Paid Search는 ~1일, Display는 ~14일이다(아래). 스펙은 ground truth 없이 AIC로 고르며, 이렇게 골라야 실데이터에 그대로 옮길 수 있다.
- 채널 기여도 — 같은 IPP 위에서 두 credit 연산자를 정의한다. BackElim(나중→처음 순서로 제거, last-touch에 집중, 입찰용)과 Shapley(128개 coalition의 한계기여 평균, 예산 배분용)다. 두 연산자의 순위 합의는 Spearman ρ = 0.929 로, 합의가 높으면 믿을 만한 신호이고 크게 갈리면 그 채널에 시너지가 크다는 진단이 된다.
- Multi-path와 두 estimand — 여정 단위 분해(위 ②)에 더해, 같은 크레딧을 누구에 대해 집계하느냐로 estimand가 갈린다. Conditional(전환자만, 사후 audit, MAE 0.012)과 Marginal G-comp(전체 유저, do(채널 제거) counterfactual = A/B가 측정하는 estimand, MAE 0.020)다. 전환자에만 조건부로 집계하면 collider bias(구급차 비유)가 끼므로, 예산 결정에는 Marginal을 쓴다.
세 관점은 하나의 효율성 항등식으로 묶이며, 검증 결과 상대오차는 0.00%였다:
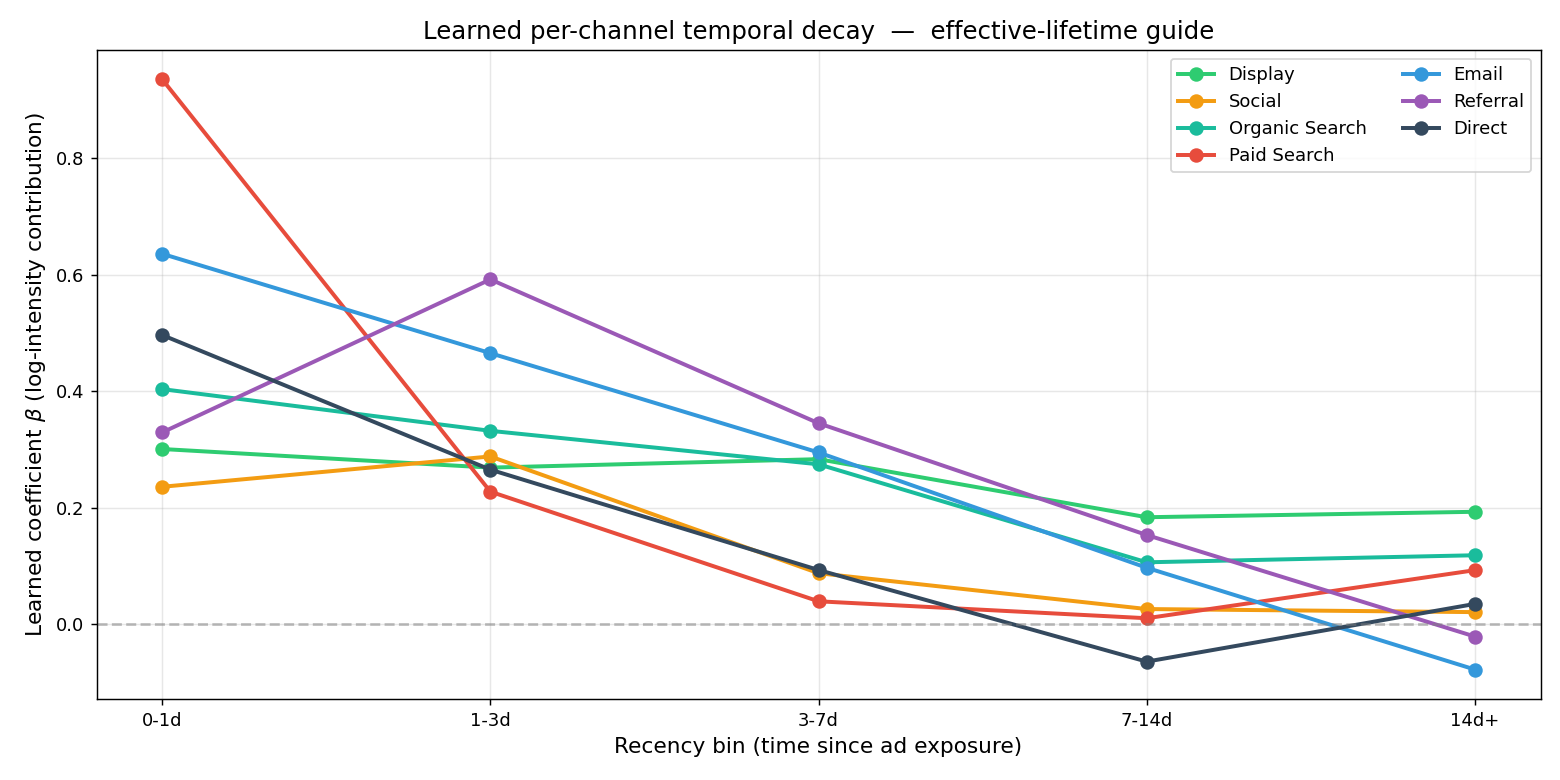 IPP가 데이터에서 학습한 채널별 감쇠(β, log-intensity 기여). Paid Search는 0–1일에 가장 강하다가 빠르게 식고(효과 수명 ~1일), Display는 2주까지 남는다. lookback window를 가정하지 않고 시간 구조를 직접 추정한 결과다.
IPP가 데이터에서 학습한 채널별 감쇠(β, log-intensity 기여). Paid Search는 0–1일에 가장 강하다가 빠르게 식고(효과 수명 ~1일), Display는 2주까지 남는다. lookback window를 가정하지 않고 시간 구조를 직접 추정한 결과다.
수식 유도(intensity·credit·estimand)와 11개 실험 전체 갤러리는 GitHub 저장소와
Methodology_05문서에 있다. 이 페이지는 핵심 서사만 담는다.
📊 임팩트 — 정직한 결과
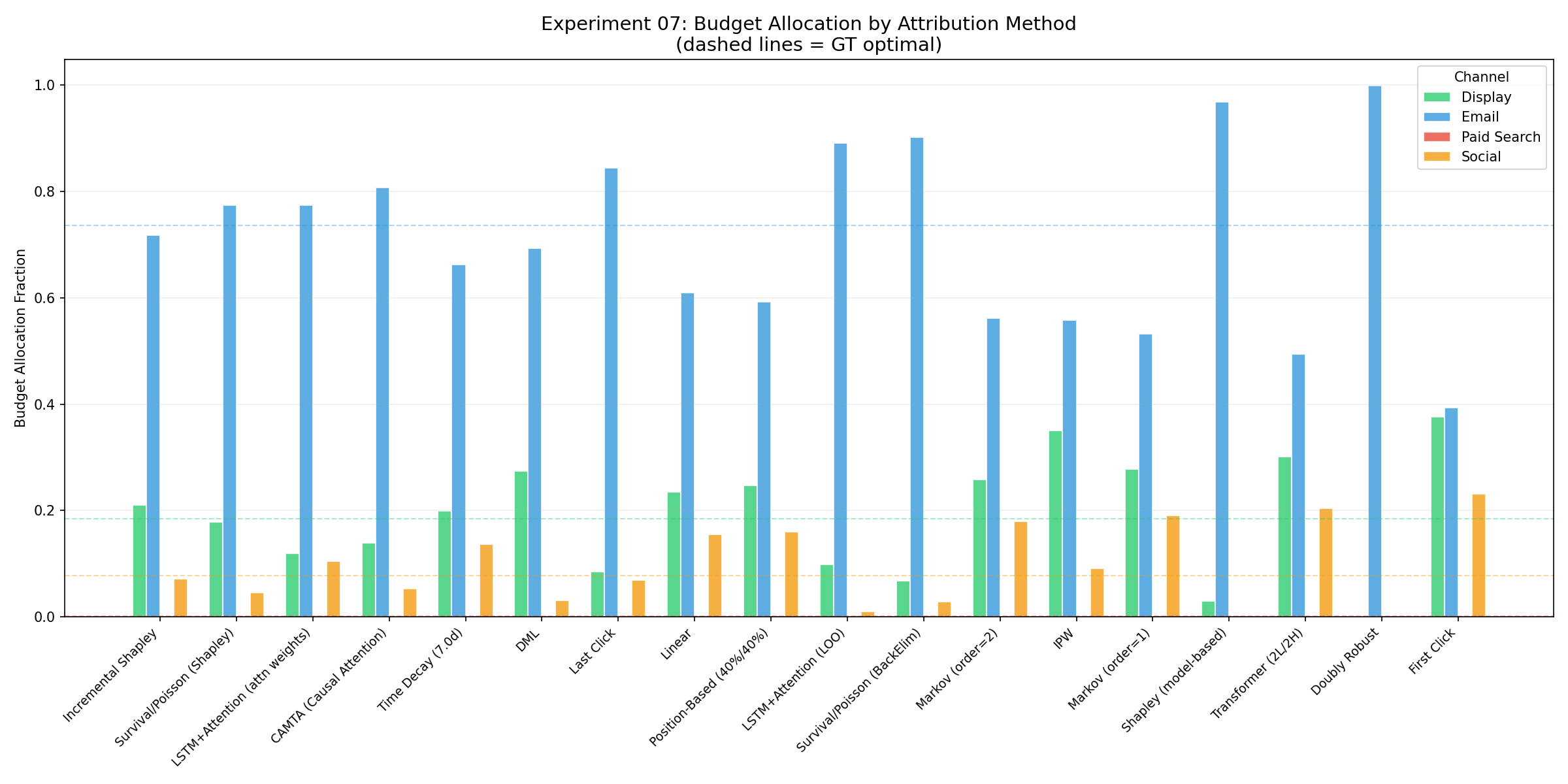
ground truth(알려진 DGP 파라미터) 대비 18개 방법을 평가했다. 메인 방법론은 정확도·안정성·의사결정 정확도를 합친 종합에서 앞서지, 어느 한 지표만의 만능 해법은 아니다.
| 방법 | 채널 MAE ↓ | Kendall τ ↑ | 예산배분 MAE ↓ | 부트스트랩 mean CV ↓ | 계열 |
|---|---|---|---|---|---|
| Survival/Poisson (Shapley) ⭐ | 0.016 (1위) | 0.905 | 0.019 (2위) | 0.13 | Causal (incremental) |
| Incremental Shapley (Du) | 0.029 | 0.905 | 0.013 (1위) | 0.60 ⚠️ | Causal (incremental) |
| CAMTA (Causal Attention) | 0.023 | 0.905 | 0.036 | 0.10 | Causal DL |
| Shapley (model-based, Total) | 0.035 | 0.905 | 0.117 ⚠️ | 0.99 ⚠️ | Game-theoretic |
| Last Click | 0.038 | 0.810 | 0.054 | 0.31 | Rule-based |
| DML / IPW | 0.050 / 0.074 | 0.524 / 0.333 | 0.045 / 0.090 | 0.93 / 0.66 | Causal (debiased) |
| Transformer (2L/2H) | 0.100 ❌ | −0.333 ❌ | — | 0.59 | Deep Learning |
| First Click | 0.158 ❌ | −0.293 ❌ | — | 0.14 | Rule-based |
(출처: results/part1/{01_method_accuracy,07_budget_optimization,10_bootstrap_stability}.csv. 부트스트랩 CV = 채널별 CV의 method-level 평균. — 는 해당 변형이 부트스트랩 대상 아님.)
정직하게 짚어둘 점 네 가지.
- “최고”라는 말은 정확히 — Survival/Poisson Shapley는 오차 1위(0.016) 이면서 변동성도 낮은(mean CV 0.13) 드문 방법이다. 정확도가 비슷한 Incremental(0.60)·Total Shapley(0.99)는 불안정하고, 가장 안정적인 Markov(~0.04)는 부정확하다. 결국 조합에서 앞설 뿐 한 축만의 만능 해법은 아니다(CAMTA가 0.023/0.10으로 가장 가까운 경쟁자다).
- 인과 기법이라고 자동으로 이기진 않는다 — debiased 추정기(DML 0.050, IPW 0.074)는 이 DGP에서 최고 규칙기반(Last Click 0.038)조차 못 이긴다. 교란이 중간 수준이라 무거운 debiasing이 별 이득을 못 본 것이다. 승부처는 IPP와 incremental 모델링 그 자체이지 propensity 보정이 아니었다.
- Total Shapley는 깨지기 쉬운 승자 — 채널 MAE 0.035는 괜찮아 보이지만, 예산 배분 0.117과 mean CV 0.99(거의 최악)로 불안정하다.
- 최고 규칙기반도 의외로 만만치 않다 — Last Click의 MAE 0.038은 나쁘지 않다. 인과 계열의 진짜 강점은 순위·배분·안정성을 한꺼번에 만족시키면서 해석 가능한 산출물(감쇠 곡선, 시너지, incremental vs total)을 함께 준다는 데 있다.
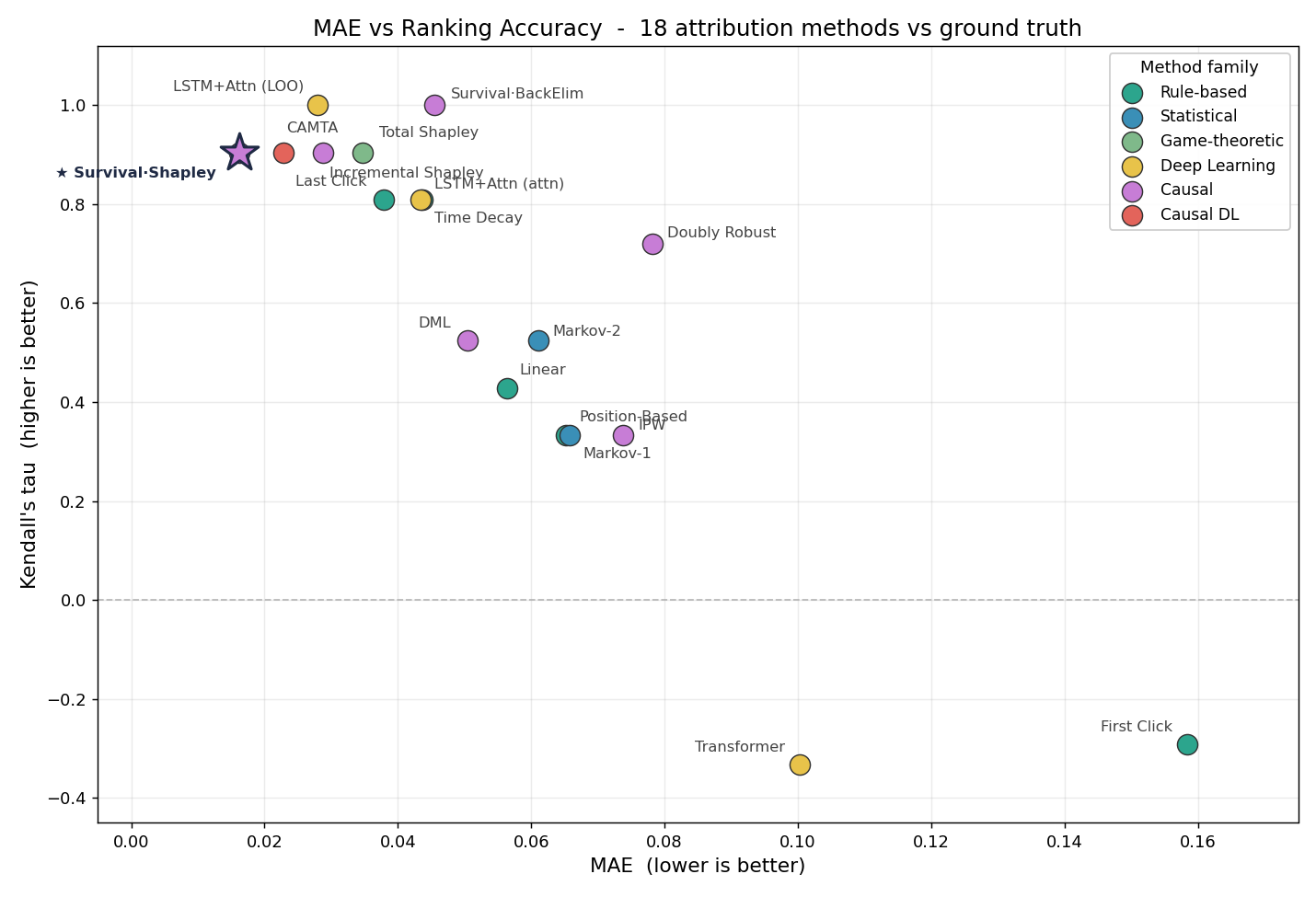 ground-truth 오차(MAE, 낮을수록 좋음)와 순위 일치도(Kendall τ, 높을수록 좋음). 인과·incremental 계열(좌상단)이 휴리스틱·예측 전용 방법(우하단, 음의 τ)과 뚜렷이 갈린다.
ground-truth 오차(MAE, 낮을수록 좋음)와 순위 일치도(Kendall τ, 높을수록 좋음). 인과·incremental 계열(좌상단)이 휴리스틱·예측 전용 방법(우하단, 음의 τ)과 뚜렷이 갈린다.
🏭 산업에서 어떻게 쓰는가 — “Effect ≠ Efficiency”
효과가 가장 강한 채널이 돈당 효율은 최악일 수 있다. attribution을 비용 구조와 결합해야 비로소 배분 결정으로 이어진다.
| 채널 | 효과 (β) | 효과 순위 | 비용/터치 | 효율 (전환/$) | GT 최적 예산 |
|---|---|---|---|---|---|
| Paid Search | 1.2 | 1위 | $2.50 (CPC) | 0.19 (꼴찌) | 0.09% ($181) |
| 0.8 | 2위 | $0.003 | 152.7 (1위) | 73.7% ($147,345) | |
| Social | 0.4 | 6위 | $0.008 (CPM) | 16.1 | 7.8% ($15,505) |
| Display | 0.3 | 7위 | $0.005 (CPM) | 38.3 | 18.5% ($36,969) |
(출처: ground_truth.json — total budget $200K, revenue/conversion $100. 효과 순위는 7개 채널 β 전체 기준; 표는 4개 paid 채널 발췌. 합성 DGP 값 — illustrative.)
 Paid Search는 효과 1위지만 CPC가 비싸 최적 예산은 0.09%에 그치고, 진짜 가치 동력은 Email(73.7%)이다. Incremental Shapley와 Survival/Poisson Shapley가 GT 최적 배분에 가장 가깝다.
Paid Search는 효과 1위지만 CPC가 비싸 최적 예산은 0.09%에 그치고, 진짜 가치 동력은 Email(73.7%)이다. Incremental Shapley와 Survival/Poisson Shapley가 GT 최적 배분에 가장 가깝다.
여정 설계 — 두 렌즈 (예산이 아니라 캠페인 질문). path-level Incremental Shapley는 35개 robust 템플릿(전환자의 15.5%)을 두 각도로 읽어 바로 실행할 수 있는 플레이북으로 바꾼다:
| 렌즈 | top 템플릿 (실측) | 액션 |
|---|---|---|
| 현 매출 주축 (total contribution) | Email→Paid Search (n=37) · Direct→Paid Search (n=24) | 방어·증폭 — 예산 유지·입찰 강화 |
| 의도 설계 후보 (mean Δ/유저) | Direct→Paid Search→Paid Search (n=5) · Email→Email→Paid Search (n=5) | 실험·확장 — A/B로 nurture 설계 |
예산은 mainstay를 지키고, 실험은 드물지만 Δ가 큰 여정을 키운다. 두 결정이 같은 효율성 항등식에서 나오므로 서로 어긋나지 않는다.
왜 이 업그레이드가 산업에 맞나 (관리자 관점). 이 전환은 모델 자랑이 아니라 예산 결정의 위험을 줄이는 변화다.
- 틀린 예산을 막는다 — Total Shapley와 규칙기반은 baseline까지 크레딧에 넣어 high-intent Paid Search에 과배분하고, 정작 효율 1위인 Email을 놓친다.
- 백본은 그대로, credit만 incremental로 바꿔도 MAE 2.9배·배분 4.4배 개선 — 같은 IPP에서 BackElim을 Shapley로 바꾼 것만으로 0.046→0.016, 0.083→0.019다. survival 백본은 규칙기반이 놓치는 우측 절단과 시간 감쇠까지 처리한다.
- 결정에 맞는 estimand — Marginal은 A/B가 재는 do(채널 제거) 효과 그 자체라, 오프라인 추정을 나중에 A/B로 검증할 수 있고 미래 예산 결정에도 들어맞는다(순위 ρ=1.000).
- 정직해서 믿을 수 있다 — 변동성이 낮아(mean CV 0.13) 그대로 보고할 수 있고, 방법을
causal — outcome-model only로 라벨해 과대주장을 피한다. 가정이 깨질 때를 대비한 다음 단계(DR/IPW 가중 survival)까지 밝혀둔다.
이 산출물은 결국 네 가지 결정으로 이어진다 — 예산 재배분, 여정 설계, 의사결정 규칙(과거는 Conditional·미래는 Marginal), 그리고 불확실성(부트스트랩 CI 게이트)이다. 핵심은 하나의 fitted IPP가 이 네 질문에 모두 답한다는 점이다.
⚠️ 한계와 정직한 스코핑
- 교란이 없다는 가정에 기댄다 — 모든 estimand는 outcome model과 충분한 confounder set 를 가정한다. 최종 기준은 여전히 A/B 테스트이고, 관측 분석은 의사결정을 돕는 도구이지 증명이 아니다.
- 모델과 DGP의 정합이 중요하다 — 생존모형은 Markov형 DGP에서는 심각하게 무너진다(그 경우 Time Decay가 MAE 1위다). 모든 DGP에서 이기는 방법은 없고, 방법마다 유리한 DGP가 따로 있다.
- 다변량 이질성 회복은 약하다 — segment와 device를 넣어도 개선이 노이즈 수준에 그친다. propensity 가중 생존모형(DR/DML 하이브리드, Tier 2)이 다음 과제다.
- 예측력은 제한적이다 — OOS AUC가 ~0.64 부근에서 방법끼리 몰려 있다(실험 08). 그래서 예측 검증은 방법을 가려내는 도구가 아니라, 너무 낮으면 기각하는 타당성 점검용으로만 쓴다.
- 결국 시뮬레이션이다 — ground truth를 얻은 대가가 합성 데이터라는 점이다. 다음 단계는 Criteo 16.5M 이벤트 규모의 검증이다(Part 2).
모든 수치는 committed 결과물(results/part1/*.csv, ground_truth.json)의 정본 값이며, 시뮬레이션 ground truth 기준이라 illustrative다. 실패하거나 약한 결과(First Click·Transformer의 음의 τ, debiased의 비우위, Total Shapley의 불안정성, Markov-DGP 붕괴)도 그대로 보고했다. 수식 유도와 11개 실험 갤러리, Quick Start는 GitHub 저장소와 Methodology 문서를 참조.