Dunnhumby — Track 1: Latent-Factor Customer Segmentation
At a Glance (TL;DR)
Three-line summary
- Applying NMF (k=5, 92.44% explained variance) + K-Means (k=7) to the Dunnhumby data (2,500 households · ~2.6M transactions · 102 weeks) yields 7 customer segments.
- The segments show high stability at Bootstrap ARI 0.77 ± 0.11 (n=100), and reveal a clear Pareto structure in which the high-value top tier (High: 0·1·6, 45.0% of all customers) accounts for roughly 73.9% of revenue.
- These descriptive segments are both a foundation for marketing strategy in their own right and a link to the moderator of Track 2’s causal targeting (causal responsiveness is validated in Track 2).
Key Numbers
| Item | Value | Note |
|---|---|---|
| Number of segments | 7 | K-Means, selected by minimum DBI + interpretability |
| NMF Latent Factor | k=5 | Explained variance 92.44% |
| Segment stability | ARI 0.77 ± 0.11 | Bootstrap n=100, 80% sample |
| Largest segment | Light Grocery 21.0% (524 households) | By customer count |
| Highest-value segment | VIP Heavy $9,716/household (12.0%) | By average revenue |
| Pareto structure | High tier 45.0% of customers → 73.9% of revenue | Confirms value concentration |
Hero Figures
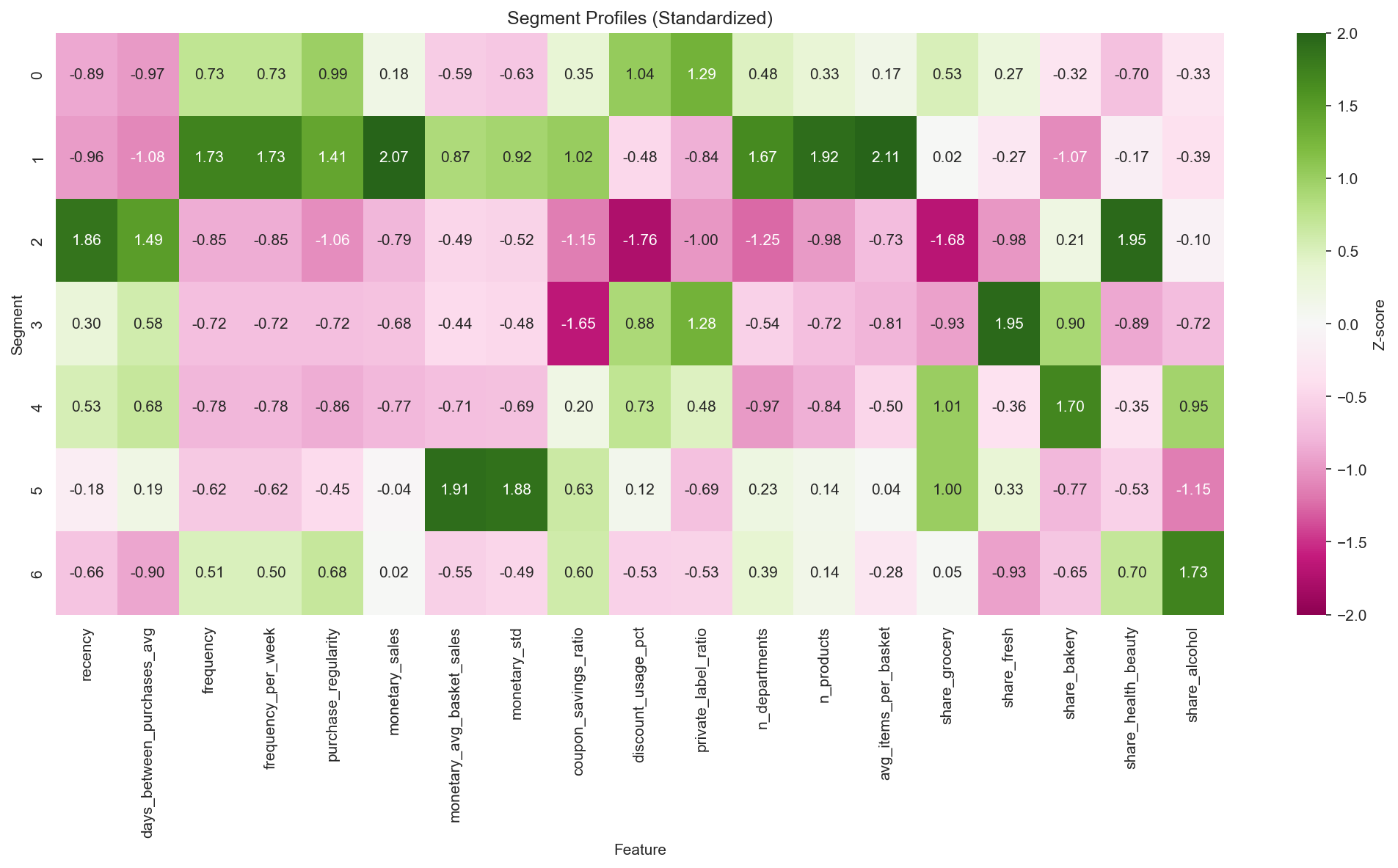 Standardized feature profile by segment (Z-scores) — shows the behavioral differentiation of the 7 segments at a glance.
Standardized feature profile by segment (Z-scores) — shows the behavioral differentiation of the 7 segments at a glance.
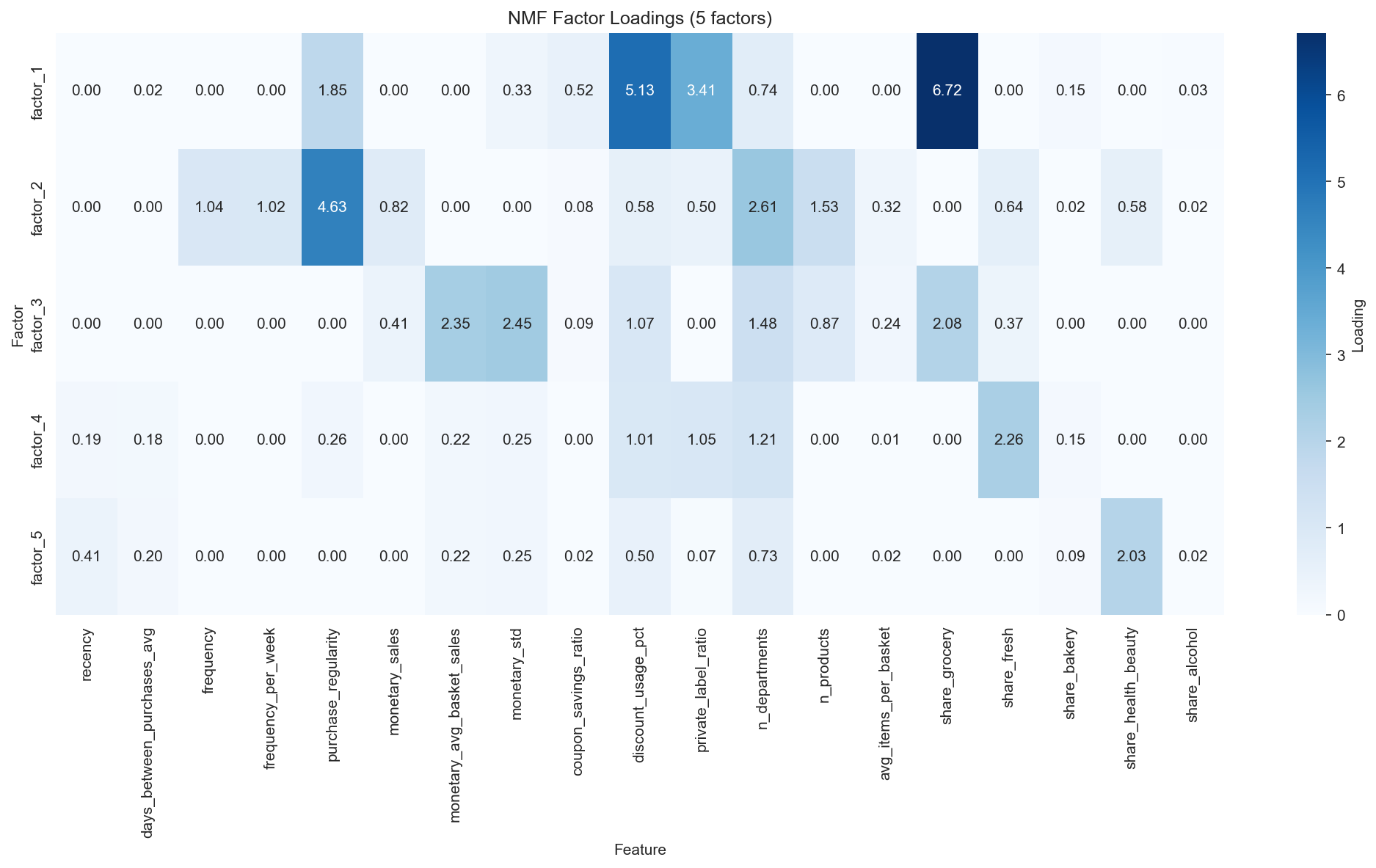 Feature loadings of the 5 NMF latent factors — separation of the Value dimensions (F2·F3) and the Need dimensions (F1·F4·F5).
Feature loadings of the 5 NMF latent factors — separation of the Value dimensions (F2·F3) and the Need dimensions (F1·F4·F5).
Table of Contents
- [30 sec] At a Glance (TL;DR)
- [5 min] Abstract · 1. Introduction · 2. Methodology · 3. Results · 4. Discussion · 5. Conclusion
- [30 min] Appendix: Technical Details (parameters · clustering-metrics full table · per-bubble-chart marketing-action mapping) · References
Abstract
This analysis presents a behavior-based customer segmentation framework using the retail transaction data from the Dunnhumby “The Complete Journey” dataset. Combining Non-negative Matrix Factorization (NMF) with K-Means Clustering, we derive 7 customer segments from 2,500 households over a 102-week observation period.
Key results:
- 5 interpretable latent factors explain 92.44% of the variance in customer behavior
- High stability of the 7 customer segments (Bootstrap ARI = 0.77 ± 0.11, n=100)
- The VIP segment (12% of all customers) generates an average of $9,716 in revenue per customer
- High-value customers (45.0%) contribute roughly 73.9% of total revenue
- Clear marketing strategies derived for each segment
This segmentation provides the foundation for a personalized marketing strategy and serves as the input to the subsequent Causal Targeting analysis (Track 2).
1. Introduction
1.1 Background
Customer segmentation is central to modern retail marketing strategy. By grouping customers based on behavioral patterns, retailers can develop targeted interventions that maximize the return on marketing investment. Traditional demographics-based segmentation often fails to capture the subtle behavioral differences that drive purchase decisions. This study adopts a behavior-first approach that discovers natural customer groups using features extracted from transaction data.
1.2 Dataset
This study analyzes the Dunnhumby “The Complete Journey” dataset:
| Item | Value |
|---|---|
| Number of households | 2,500 |
| Number of transactions | ~2.6 million (2,595,732) |
| Analysis period | 102 weeks (2 years) |
| Number of campaigns | 30 marketing campaigns |
| Number of products | 92,000+ SKUs |
| Number of stores | 400+ |
The dataset includes transaction records, household demographics (32% coverage), campaign targeting, and coupon distribution and redemption data.
1.3 Research Objectives
- Extract latent behavioral factors that characterize customer shopping patterns
- Identify distinct customer segments that yield actionable marketing implications
- Validate segment stability through bootstrap resampling
- Develop per-segment marketing strategies / recommendations
1.4 Analysis Framework
This analysis is part of a 2-track research framework:
- Track 1 (this report): Customer understanding through segmentation
- Track 2 (separate): Causal targeting through heterogeneous treatment effect estimation
The Track 1 segments serve as moderators for the Track 2 causal analysis, enabling per-segment campaign optimization.
2. Methodology
2.1 Feature Engineering
We constructed 33 customer-level features from the transaction data, organized into 6 conceptual groups:
| Group | Count | Description | Examples |
|---|---|---|---|
| Recency | 6 | Time since last purchase | days_since_last, active_last_4w |
| Frequency | 6 | Shopping frequency patterns | visits_per_week, purchase_regularity |
| Monetary | 7 | Spending characteristics | total_sales, avg_basket_size, coupon_savings |
| Behavioral | 7 | Shopping behavior | discount_rate, private_label_ratio, n_departments |
| Category | 6 | Category preferences | share_grocery, share_fresh, share_h&b |
| Time | 1 | Tenure coverage | week_coverage |
To address multicollinearity, we removed highly correlated pairs (), reducing the feature set from 33 to 19.
Multicollinearity handling details:
| Removal criterion | Examples of removed features | Retained feature |
|---|---|---|
| Perfect correlation (r = 1.0) | frequency_per_month | frequency_per_week |
| High correlation (r ≥ 0.9) | monetary_actual | monetary_sales |
| Redundant information (r ≥ 0.7) | active_last_12w | active_last_4w |
The 14 removed features:
- Frequency: frequency_per_month, transaction_count
- Monetary: monetary_actual, monetary_avg_basket_actual, monetary_per_week
- Recency: active_last_12w, recency_weeks
- Behavioral: avg_products_per_basket
- Other redundant derived variables
Note: We chose correlation-based removal over VIF analysis because (1) it maintains compatibility with NMF’s non-negativity constraint, and (2) it prioritizes interpretability. As an alternative, automatic variable selection via Elastic Net regularization is also possible, but here we secured reproducibility through explicit removal.
Preprocessing: For NMF compatibility, MinMaxScaler normalization was applied to the [0, 1] range (non-negative input required).
2.2 Latent Factor Modeling (NMF)
Non-negative Matrix Factorization (NMF) decomposes the customer-feature matrix into two low-dimensional matrices to derive latent behavioral factors.
Rationale for NMF vs PCA:
| Criterion | NMF | PCA |
|---|---|---|
| Interpretability | Parts-based decomposition → intuitive factor interpretation | Orthogonal axes → hard to interpret |
| Non-negativity constraint | Naturally non-negative loadings | Allows negative loadings |
| Business fit | ”Customer A = 0.3×loyal + 0.5×fresh” is interpretable | ”Customer A = PC1 - 0.2×PC2” is unclear |
| Marketing collaboration | Easy to communicate with non-technical teams via additive-parts interpretation | Requires technical explanation |
| Prior research | Widely used in retail segmentation (Lee & Seung, 1999) | General dimensionality reduction |
Empirical validation: At the same k, we confirmed that NMF factors produce clearer clustering than PCA components in terms of category/behavior.
Model selection:
- n_components: evaluated over the range 2–8
- Selection criteria: reconstruction error (elbow method) and factor interpretability
- Selected: 5 components (explaining 92.44% of variance)
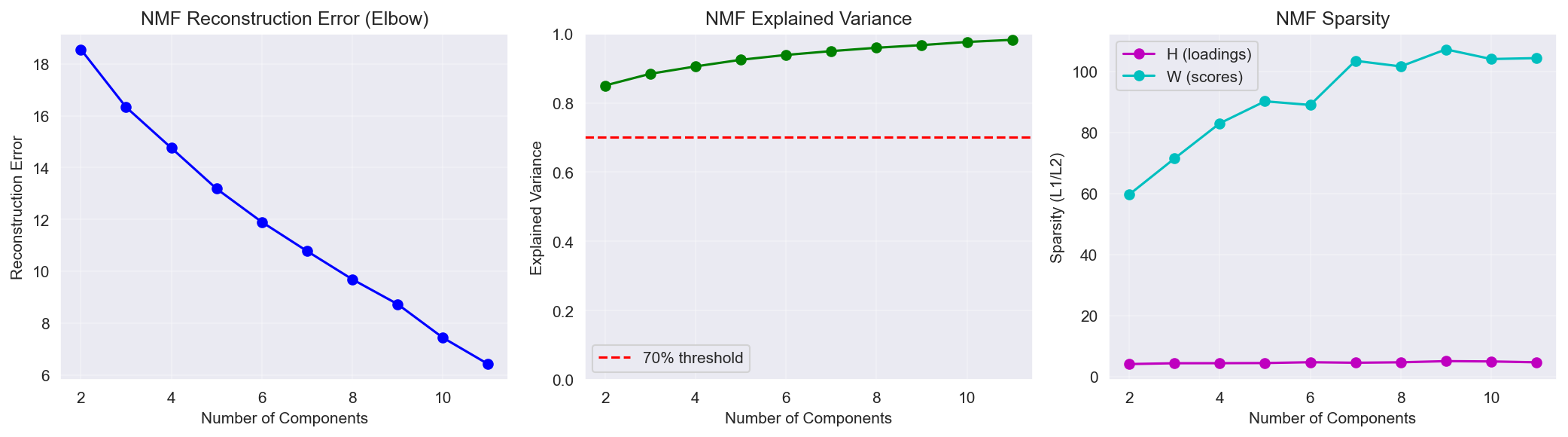 Figure 1: NMF component selection — reconstruction error and cumulative explained variance.
Figure 1: NMF component selection — reconstruction error and cumulative explained variance.
NMF parameters:
- Solver: Coordinate Descent
- Initialization: Random
- Max iterations: 1,000
- Random state: fixed for reproducibility
2.3 Clustering
We applied K-Means clustering to the NMF factor scores to identify customer segments.
Clustering evaluation:
- Tested over the range k = 2–11
- Compared K-Means vs. Gaussian Mixture Model (GMM)
- K-Means substantially outperformed GMM (Silhouette: 0.219 vs. 0.047)
Optimal-k selection (an honest trade-off):
The internal validation metrics for the candidate k values are below (full table in Appendix A.5):
| k | Silhouette | Calinski-Harabasz | Davies-Bouldin |
|---|---|---|---|
| 3 | 0.271 | 984.9 | 1.256 |
| 5 | 0.225 | 794.2 | 1.321 |
| 6 | 0.207 | 756.3 | 1.342 |
| 7 | 0.219 | 732.0 | 1.241 ← selected |
| 8 | 0.209 | 700.2 | 1.244 |
- Davies-Bouldin Index (DBI): minimized at k = 7 (1.241) — the best cluster separation among the candidates.
- The Silhouette Score is in fact highest at lower k (max 0.271 at k=3). The Silhouette at k=7 (0.219) is not the maximum, and we do not claim it to be “optimal.”
- Selected: k = 7 — a decision integrating (1) DBI minimization, (2) business interpretability/actionability (the 7 segments map naturally to marketing actions), and (3) high bootstrap stability (ARI 0.77). In other words, this is not a single-metric optimum but a choice balanced across a quantitative indicator (DBI), a qualitative criterion (actionability), and robustness (ARI).
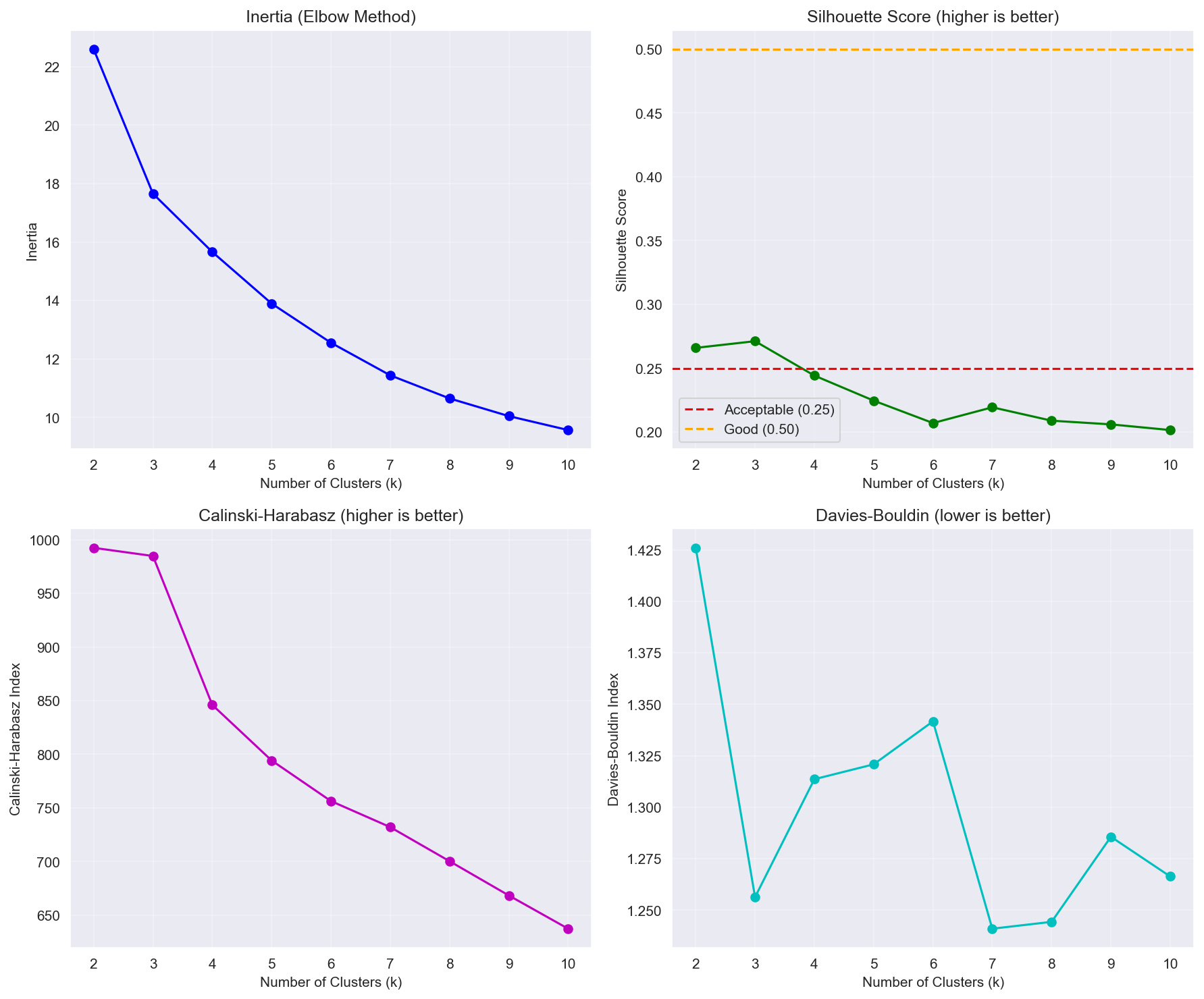 Figure 2: Clustering evaluation metrics as a function of k. Silhouette is higher at lower k, while DBI is minimized at k=7.
Figure 2: Clustering evaluation metrics as a function of k. Silhouette is higher at lower k, while DBI is minimized at k=7.
2.4 Stability Validation
We performed bootstrap resampling to assess segment stability:
- 100 bootstrap iterations
- 80% sample ratio per iteration
- Metric: Adjusted Rand Index (ARI) between the original and bootstrap assignments
3. Results
3.1 Latent Factor Interpretation
Through NMF, we identified 5 interpretable latent factors representing distinct aspects of customer behavior:
| Factor | Name | Top features (loading) | Interpretation |
|---|---|---|---|
| F1 | Grocery Deal Seeker | share_grocery (6.72), discount_usage_pct (5.13), private_label_ratio (3.41) | Budget-conscious grocery shoppers who seek discounts |
| F2 | Loyal Regular | purchase_regularity (4.63), n_departments (2.61), n_products (1.53), frequency (1.04) | High-engagement one-stop shoppers |
| F3 | Big Basket | monetary_std (2.45), monetary_avg_basket (2.35), share_grocery (2.08) | Irregular bulk buyers |
| F4 | Fresh Focused | share_fresh (2.26), n_departments (1.21) | Fresh-food category specialists |
| F5 | Health & Beauty | share_health_beauty (2.03), recency (0.41) | Drugstore-type shoppers |
Figure 3: NMF factor loadings heatmap — feature weights for each latent factor.
The factors separate naturally into a Value dimension (F2, F3, capturing frequency and monetary value) and a Need dimension (F1, F4, F5, capturing category preference).
3.2 Clustering Evaluation Metrics
| Metric | Value | Interpretation |
|---|---|---|
| Explained Variance | 92.44% | High factor coverage |
| Silhouette Score (k=7) | 0.219 | Adequate for behavioral data (benchmark 0.15–0.30); note the max is at k=3 (0.271) |
| Calinski-Harabasz Index | 732.0 | High between-cluster variance |
| Davies-Bouldin Index | 1.241 | Minimum among candidate k (best separation) |
| Bootstrap ARI | 0.77 ± 0.11 | High stability (95% CI: 0.55–0.99) |
Silhouette Score interpretation:
A Silhouette Score of 0.219 is moderate, and in this data it is higher at lower k (k=3). However, this is a common pattern in behavioral clustering, where customer characteristics exist on a continuum rather than in discrete groups. We make clear that k=7 is not the Silhouette optimum but a choice based on DBI minimization + interpretability + stability criteria (§2.3).
| Comparison | Silhouette | Source |
|---|---|---|
| This study (k=7) | 0.219 | - |
| Retail segmentation (general) | 0.15–0.30 | Wedel & Kamakura (2000) |
| E-commerce clustering | 0.15–0.30 | Industry benchmark |
| Demographics-based segmentation | 0.35–0.50 | Higher separation from discrete attributes |
Causes of the low Silhouette:
- Customer behavior is inherently continuously distributed (no discrete boundaries)
- RFM and category preferences form a gradient
- Transitional customers exist between segments (e.g., Light Grocery → Active Loyalists in transition)
Acceptability assessment: 0.219 is within the benchmark range in the context of behavioral data, and the facts that DBI is minimized at k=7 and that the high Bootstrap ARI (0.77) complement each other reinforce the substantive stability of the segments.
3.3 Stability Validation
Bootstrap resampling (100 iterations, 80% sample) yielded an Adjusted Rand Index of 0.77 ± 0.11, indicating high segment stability. An ARI of 0.70 or above is generally considered strong agreement, confirming that the 7-segment solution is robust to sampling variation.
3.4 The 7 Customer Segments
Clustering identified 7 distinct customer segments (over all 2,500 households):
| Seg | Name | Size | Avg revenue | Frequency | Recency | Regularity | Primary factor |
|---|---|---|---|---|---|---|---|
| 0 | Active Loyalists | 509 (20.4%) | $3,878 | 171 | 6 days | 0.78 | F2 (Loyal) |
| 1 | VIP Heavy | 299 (12.0%) | $9,716 | 256 | 4 days | 0.88 | F2 (Loyal) |
| 2 | Lapsed H&B | 193 (7.7%) | $872 | 37 | 75 days | 0.25 | F5 (H&B) |
| 3 | Fresh Lovers | 339 (13.6%) | $1,233 | 48 | 36 days | 0.34 | F4 (Fresh) |
| 4 | Light Grocery | 524 (21.0%) | $942 | 43 | 42 days | 0.30 | F1 (Grocery-Deal) |
| 5 | Bulk Shoppers | 318 (12.7%) | $3,206 | 56 | 24 days | 0.41 | F3 (Basket) |
| 6 | Regular + H&B | 318 (12.7%) | $3,393 | 152 | 12 days | 0.70 | F2 (Loyal) |
Note: We label the primary factor of Seg4 (Light Grocery) as F1 (Grocery-Deal) — this segment has grocery share 0.56 + discount 0.51 loading strongly on F1, so a grocery/discount-seeking tendency dominates.
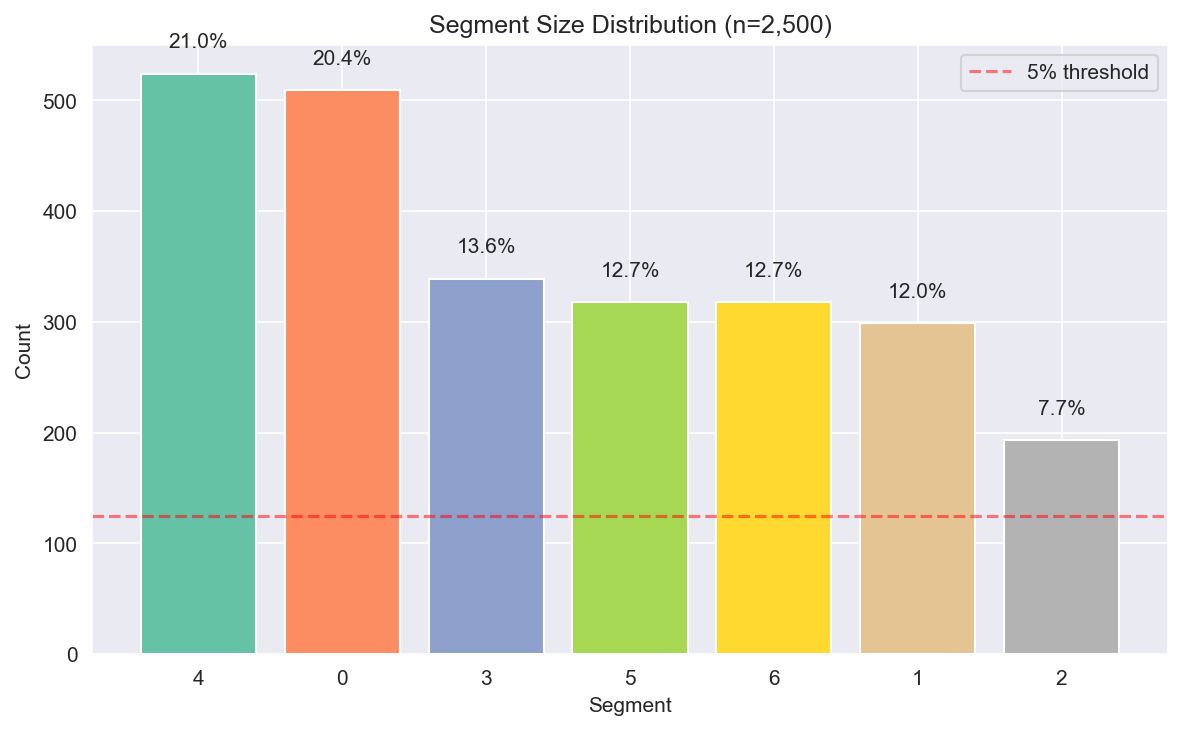 Figure 4: Customer segment size distribution.
Figure 4: Customer segment size distribution.
3.5 Segment Profiles
Figure 5: Standardized feature profile by segment (Z-scores).
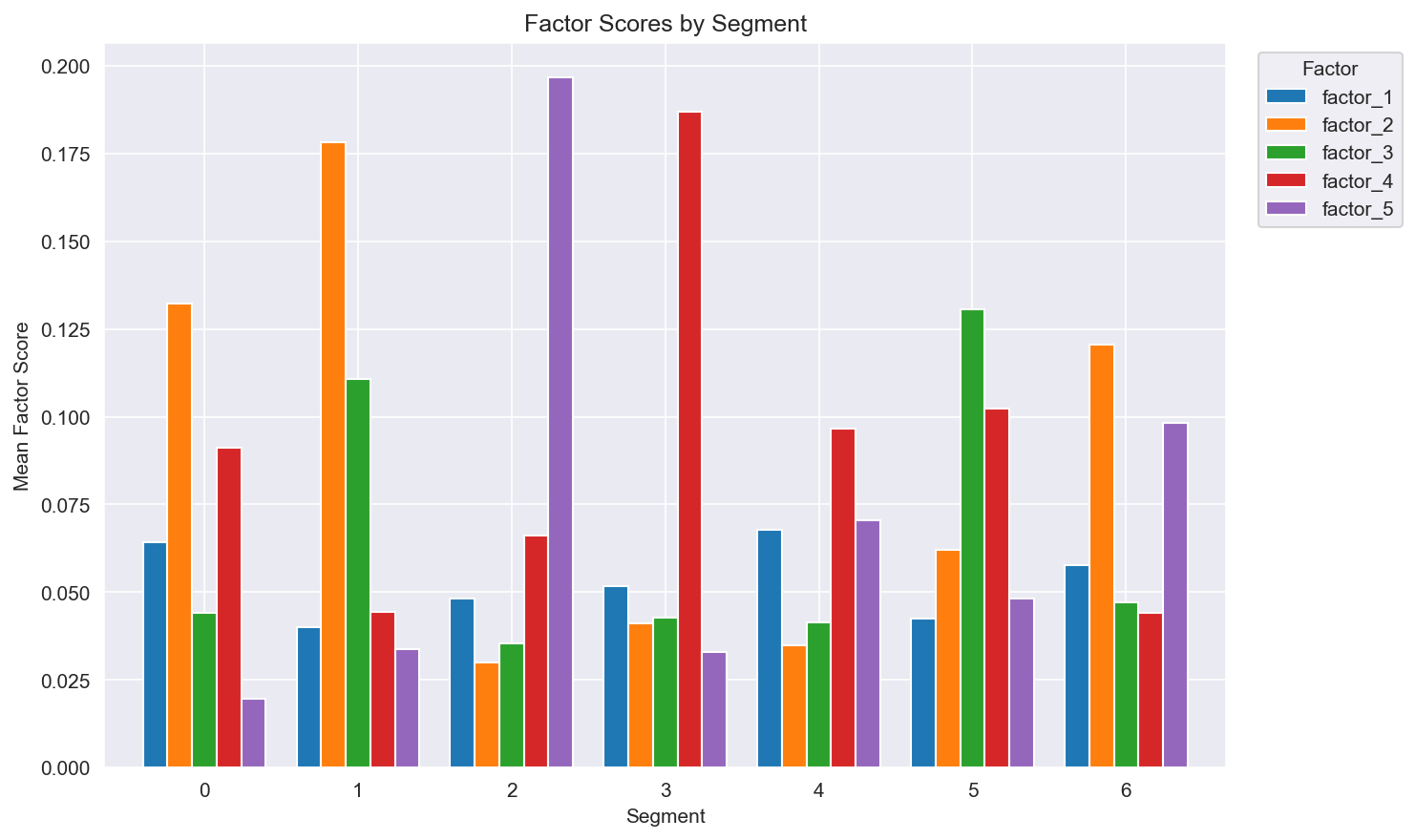 Figure 6: Average factor score for each customer segment.
Figure 6: Average factor score for each customer segment.
Segment characteristics:
Segment 0: Active Loyalists (20.4%)
- High purchase regularity (0.78) and diverse category shopping
- Strong private-label preference (highest PL ratio at 0.34)
- Budget-conscious yet highly loyal shoppers
Segment 1: VIP Heavy (12.0%)
- Top performance on every RFM metric
- Highest frequency (256), monetary value ($9,716), lowest recency (4 days)
- True one-stop shoppers buying an average of 1,316 unique products
Segment 2: Lapsed H&B (7.7%)
- Highest recency (75 days) — effectively churned
- H&B category specialists with low overall engagement
- Win-back targets with uncertain ROI
Segment 3: Fresh Lovers (13.6%)
- Fresh-food category specialists with moderate engagement
- Relatively active customers (36-day recency) with concentrated baskets
Segment 4: Light Grocery (21.0%)
- The largest segment by customer count, with the lowest value per customer ($942)
- Light engagement centered on groceries/discounts (F1 Grocery-Deal dominant)
- An activation opportunity with habit-formation potential
Segment 5: Bulk Shoppers (12.7%)
- Highest average basket size (about $57 per visit)
- Low frequency (56) but high spend per visit
- Warehouse/Costco-style shopping pattern
Segment 6: Regular + H&B (12.7%)
- A second-tier value segment with VIP-conversion potential
- Regular buyers (152) with an H&B focus
3.6 Value Tier Distribution
The segments separate naturally into value tiers (over all 2,500 households):
| Tier | Segments | N | Customer share | Avg revenue | Total revenue | Revenue share |
|---|---|---|---|---|---|---|
| High | 0, 1, 6 | 1,126 | 45.0% | $5,291 | $5,958K | 73.9% |
| Medium | 3, 5 | 657 | 26.3% | $2,188 | $1,437K | 17.8% |
| Low/At-Risk | 2, 4 | 717 | 28.7% | $923 | $662K | 8.2% |
| Total | - | 2,500 | 100% | $3,223 | $8,057K | 100% |
Calculation basis:
- Total revenue = Σ(segment N × average revenue)
- Revenue share = tier total revenue / overall total revenue
- High Value segments: Active Loyalists ($3,878), VIP Heavy ($9,716), Regular+H&B ($3,393)
- (The totals above were recomputed from the corrected per-segment average revenue and reflect the canonical LEDGER values such as Seg4 $942.)
Pareto-law check: The top 45% of customers (High Value) contribute 73.9% of revenue, confirming a clear value-concentration phenomenon close to the classic 80/20 rule.
3.7 Multidimensional Segment Positioning
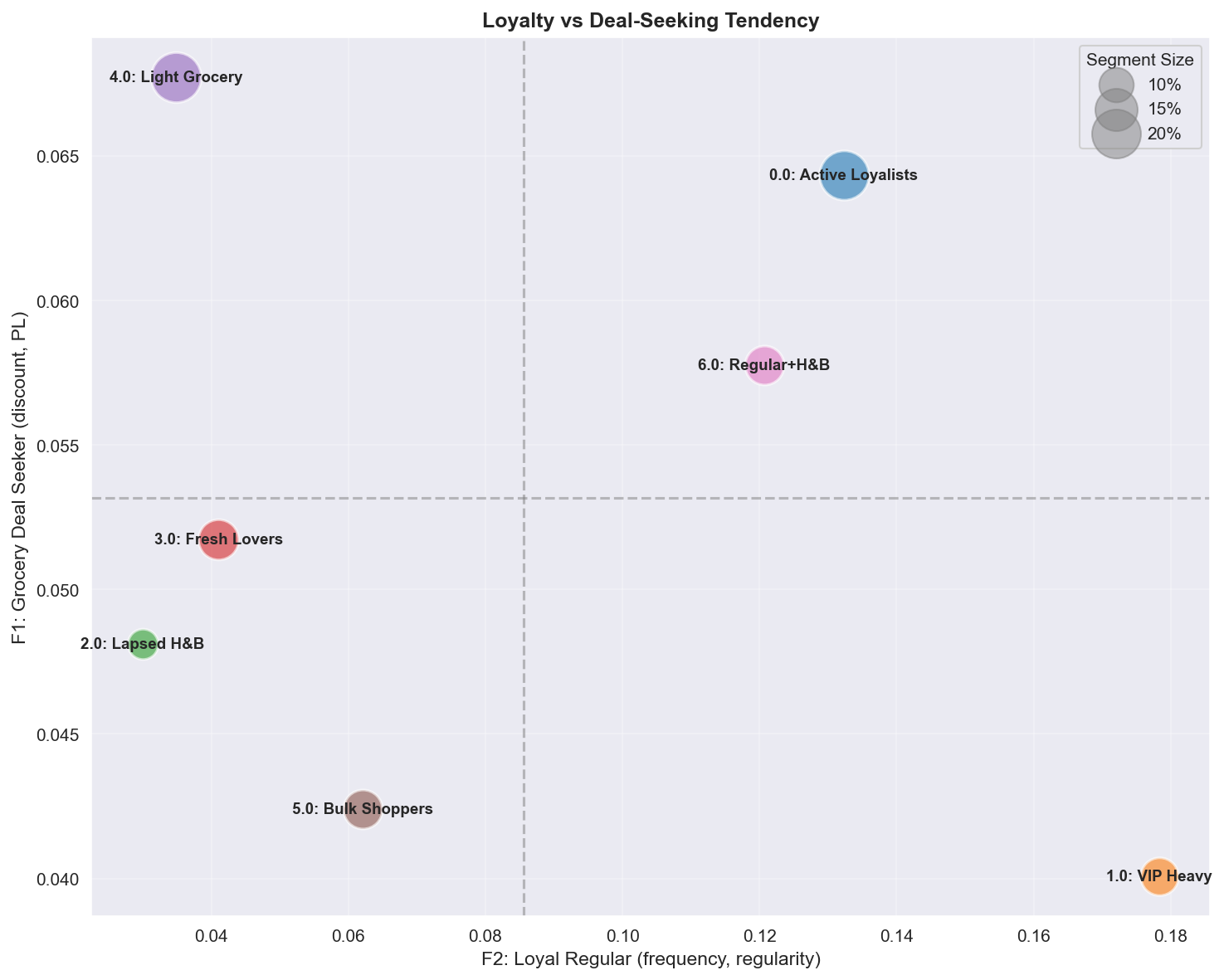 Figure 7: Segment positioning on the Loyalty (F2) vs Deal-Seeking (F1) dimensions.
Figure 7: Segment positioning on the Loyalty (F2) vs Deal-Seeking (F1) dimensions.
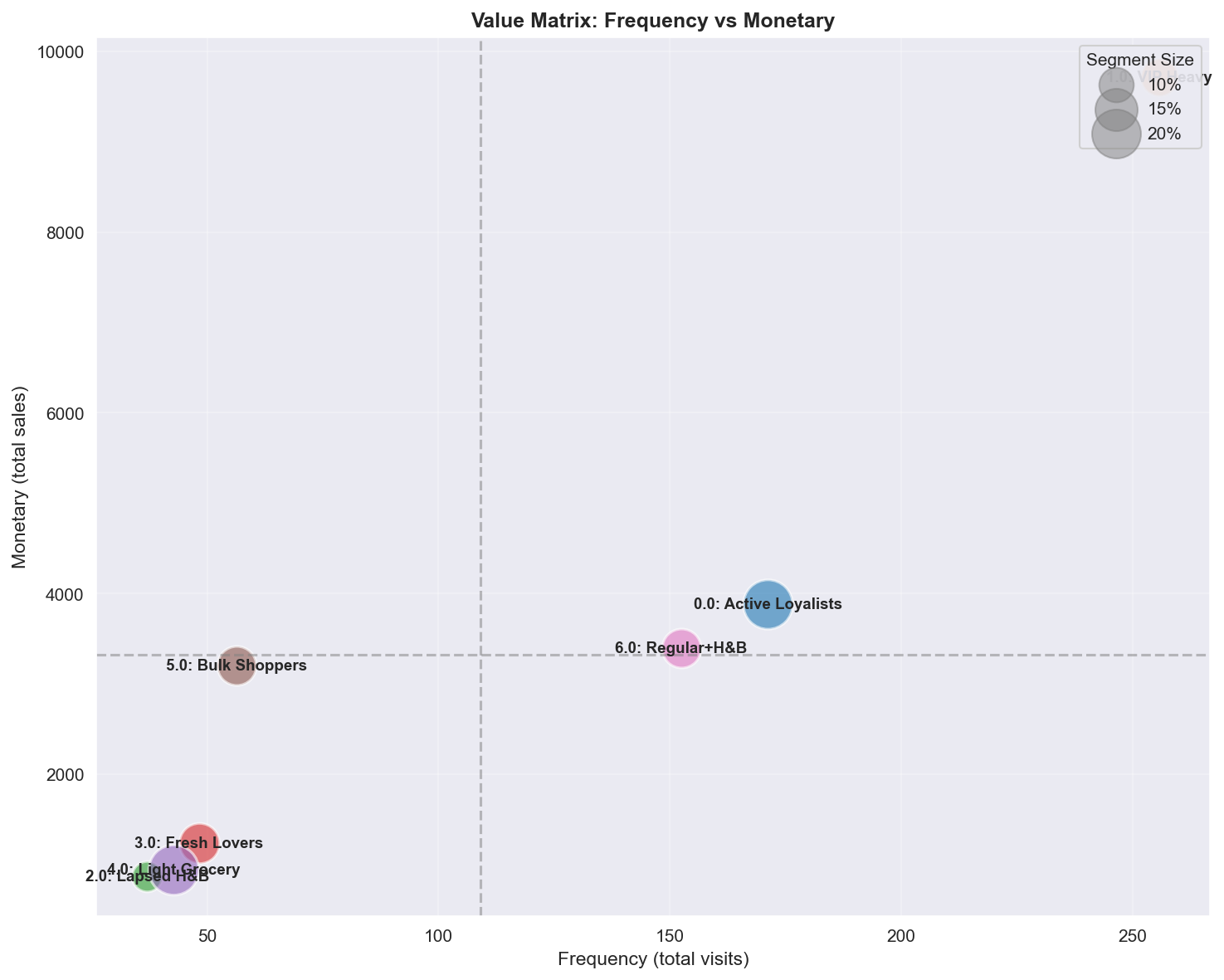 Figure 8: RFM value positioning showing VIP dominance and segment differentiation.
Figure 8: RFM value positioning showing VIP dominance and segment differentiation.
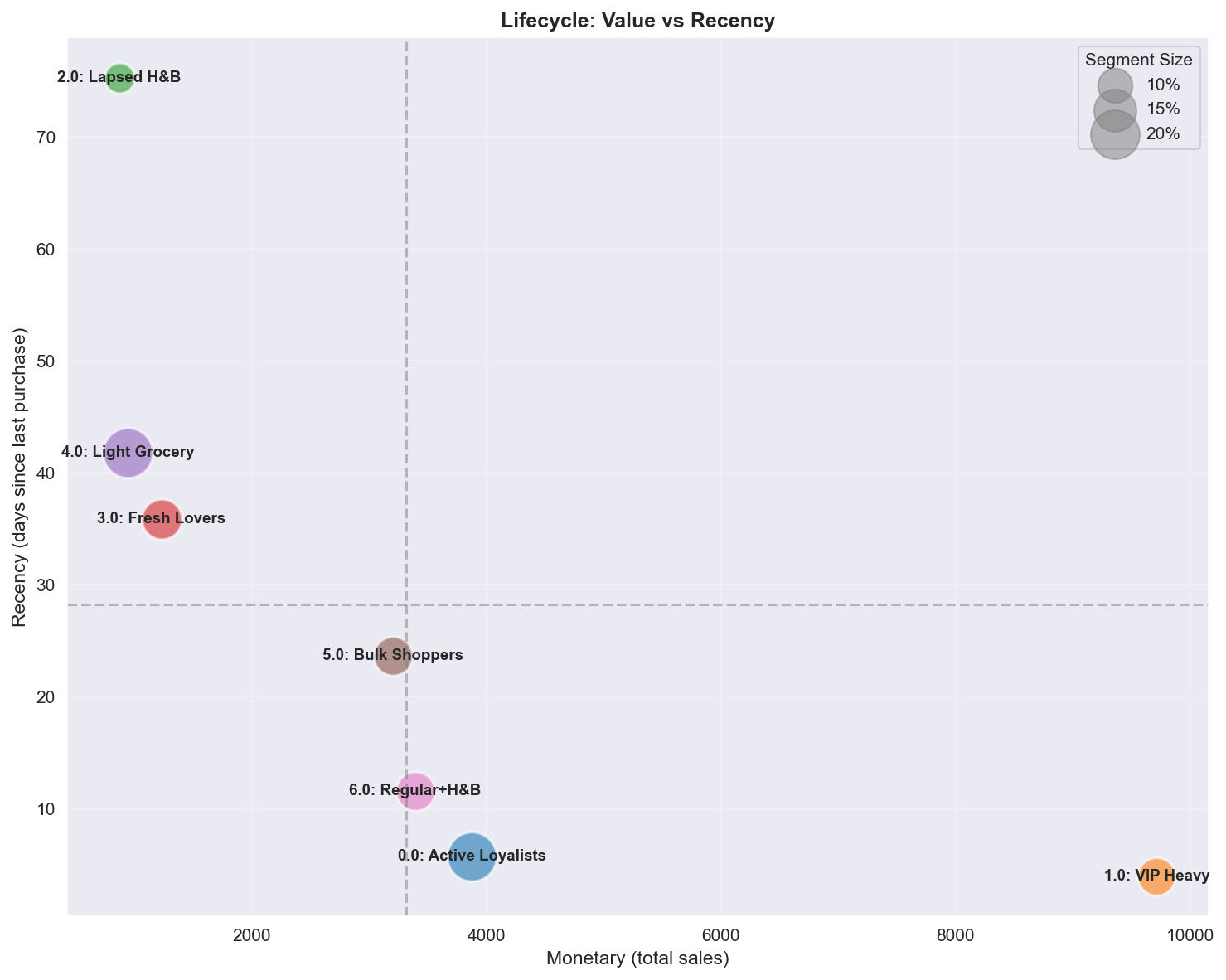 Figure 9: Customer lifecycle positioning identifying active high-value and lapsed segments.
Figure 9: Customer lifecycle positioning identifying active high-value and lapsed segments.
4. Discussion
4.1 Key Insights
1. A clear value hierarchy The segmentation shows a clear Pareto distribution: 45.0% of high-value segments contribute roughly 73.9% of estimated revenue. VIP Heavy (12%) alone is the most important retention target.
2. Behavioral differentiation The factors successfully separate customers along both the Value (frequency, monetary) and Need (category preference) dimensions. This dual structure enables both value-based prioritization and need-based personalization.
3. Lifecycle stages The segments map to distinct lifecycle stages:
- Active/Growing: Segments 0, 1, 6 (low recency, high engagement)
- Stable: Segments 3, 4, 5 (medium recency)
- Declining/Churned: Segment 2 (high recency, low engagement)
4. Category specialists Fresh Lovers (13.6%) and the H&B-focused segments show category specialization, suggesting opportunities for category-specific marketing approaches.
4.2 Marketing Strategy / Recommendations
| Segment | Priority | Strategy | Key actions |
|---|---|---|---|
| VIP Heavy | High | Retention | Premium perks, churn-prediction alerts, exclusive access |
| Active Loyalists | High | Strengthen | Private-label promotions, loyalty points, basket expansion |
| Regular + H&B | Medium | Upgrade | VIP-conversion program, cross-category incentives |
| Bulk Shoppers | Medium | Regularize | Subscription offers, scheduled delivery, bundle deals |
| Fresh Lovers | Medium | Engage | Fresh-food content marketing, daily specials, recipe inspiration |
| Light Grocery | Low | Activate | Habit-formation campaigns, progressive rewards, onboarding |
| Lapsed H&B | Low | Win-back | Re-engagement campaigns, H&B-focused offers |
Recommended budget allocation:
- High Priority (60%): VIP Heavy (25%), Active Loyalists (20%), Regular + H&B (15%)
- Medium Priority (30%): Bulk Shoppers (10%), Fresh Lovers (10%), Light Grocery (10%)
- Low Priority (10%): Lapsed H&B (10%)
Caution (descriptive vs. causal): The allocation above is a priority based on descriptive value (revenue contribution). “Which segment actually responds better to promotions” is a separate causal question, validated in Track 2 via per-segment CATE — and that result may differ from the revenue-value ranking (e.g., a high-value segment does not necessarily have a high treatment effect).
4.3 Limitations
1. Moderate Silhouette Score (0.219) Behavioral data is inherently continuous rather than having discrete boundaries. In this data, the Silhouette is higher at lower k (k=3), so k=7 is not the Silhouette optimum but a choice based on DBI minimization, interpretability, and stability. This score is acceptable for customer segmentation but indicates some overlap between segments.
2. Limited demographics coverage (32%) Only 801 of the 2,500 households have demographic information, which limits demographics-based stratification and persona development.
3. Descriptive vs. causal This segmentation is descriptive. Questions such as “which segment responds best to promotions?” require causal analysis (Track 2).
4. Single-retailer context The results are specific to this retailer’s customer base and may not generalize to other retail contexts.
4.4 Future Directions
1. Track 2 integration The segments will serve as heterogeneous-treatment-effect moderators in the Track 2 causal analysis. This enables per-segment campaign-effect estimation.
2. A/B testing validation The recommended strategies should be validated through controlled experiments before full-scale deployment.
3. Dynamic segmentation Periodic re-clustering to capture segment migration and evolving customer behavior.
4. Value × Need framework An optional extension using separate Value (RFM) and Need (Category) factor models for cross-sell optimization scenarios.
5. Conclusion
This study demonstrates an effective approach to behavior-based customer segmentation using latent factor modeling and clustering. The NMF + K-Means framework successfully identified 7 distinct customer segments with high stability (ARI = 0.77 ± 0.11) and clear business interpretability.
Key achievements:
- 5 latent factors (92.44% explained variance) capturing the Value (Loyalty, Monetary) and Need (Category Preference) dimensions
- 7 actionable segments ranging from VIP Heavy ($9,716 average) to Lapsed H&B ($872 average)
- A clear priority hierarchy including the 45.0% of high-value customers (contributing 73.9% of revenue) that warrant concentrated retention efforts
- Per-segment strategies from Retention (VIP) to Activation (Light Grocery) to Win-back (Lapsed)
The segmentation provides a solid foundation for personalized marketing and serves as the input to the subsequent Causal Targeting analysis, enabling evidence-based marketing optimization.
Appendix: Technical Details
A.1 Software Environment
- Python 3.9+
- scikit-learn (NMF, K-Means)
- pandas, numpy (data processing)
- matplotlib, seaborn (visualization)
A.2 Reproducibility
- Random seed fixed for all stochastic processes
- Full code available in the project notebooks:
01_feature_engineering.ipynb02_customer_profiling.ipynb
A.3 Data Artifacts
- Segment assignments:
data/dunnhumby/processed/segment_models.joblib - Feature metadata:
data/dunnhumby/processed/feature_metadata.json
A.4 Segment Positioning Analysis: Marketing Actions by Bubble Chart
This section provides detailed marketing interpretations for each 2D segment-positioning chart.
A.4.1 Loyalty (F2) vs Deal-Seeking (F1)
| Quadrant | Segments | Profile | Marketing action |
|---|---|---|---|
| High Loyalty + High Deal | Active Loyalists | Loyal but price-sensitive | PB promotions, loyalty points tied to discount triggers |
| High Loyalty + Low Deal | VIP Heavy | Premium loyal customers | Exclusive access, premium service, avoid discounts |
| Low Loyalty + High Deal | Light Grocery, Fresh Lovers | Cherry-pickers | Convert to loyalty via progressive rewards |
| Low Loyalty + Low Deal | Lapsed H&B, Bulk Shoppers | Churned or transactional relationship | Win-back or accept low engagement |
A.4.2 Loyalty (F2) vs Big Basket (F3)
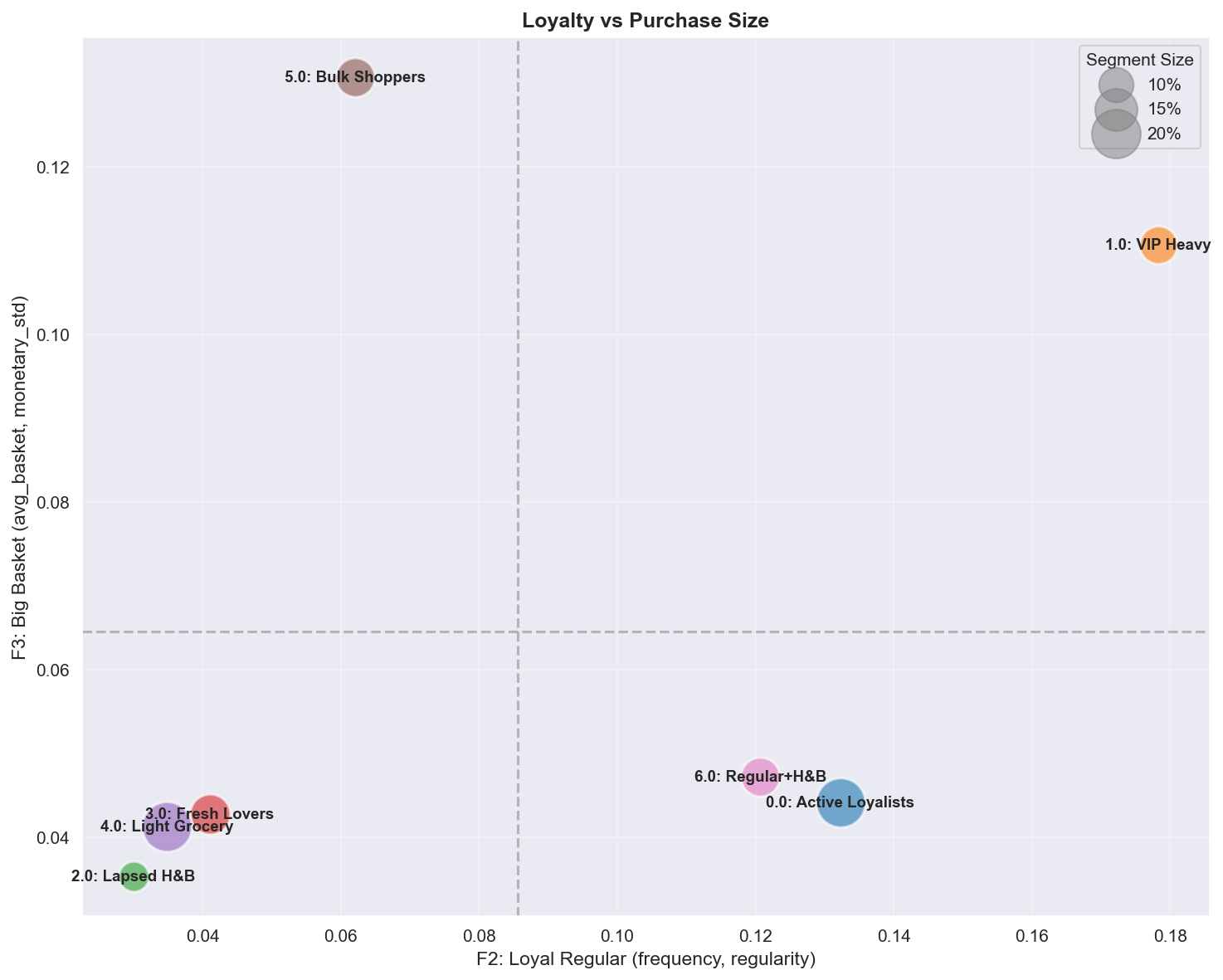
| Quadrant | Segments | Profile | Marketing action |
|---|---|---|---|
| High Loyalty + High Basket | VIP Heavy | One-stop power shoppers | Retention focus, personalized recommendations |
| High Loyalty + Low Basket | Active Loyalists, Regular+H&B | Frequent small baskets | Cross-sell, expand basket with bundle offers |
| Low Loyalty + High Basket | Bulk Shoppers | Irregular bulk buying | Subscription model, scheduled-delivery incentives |
| Low Loyalty + Low Basket | Lapsed, Light Grocery | Minimal engagement | Activation campaigns, habit formation |
A.4.3 Fresh (F4) vs Health & Beauty (F5)
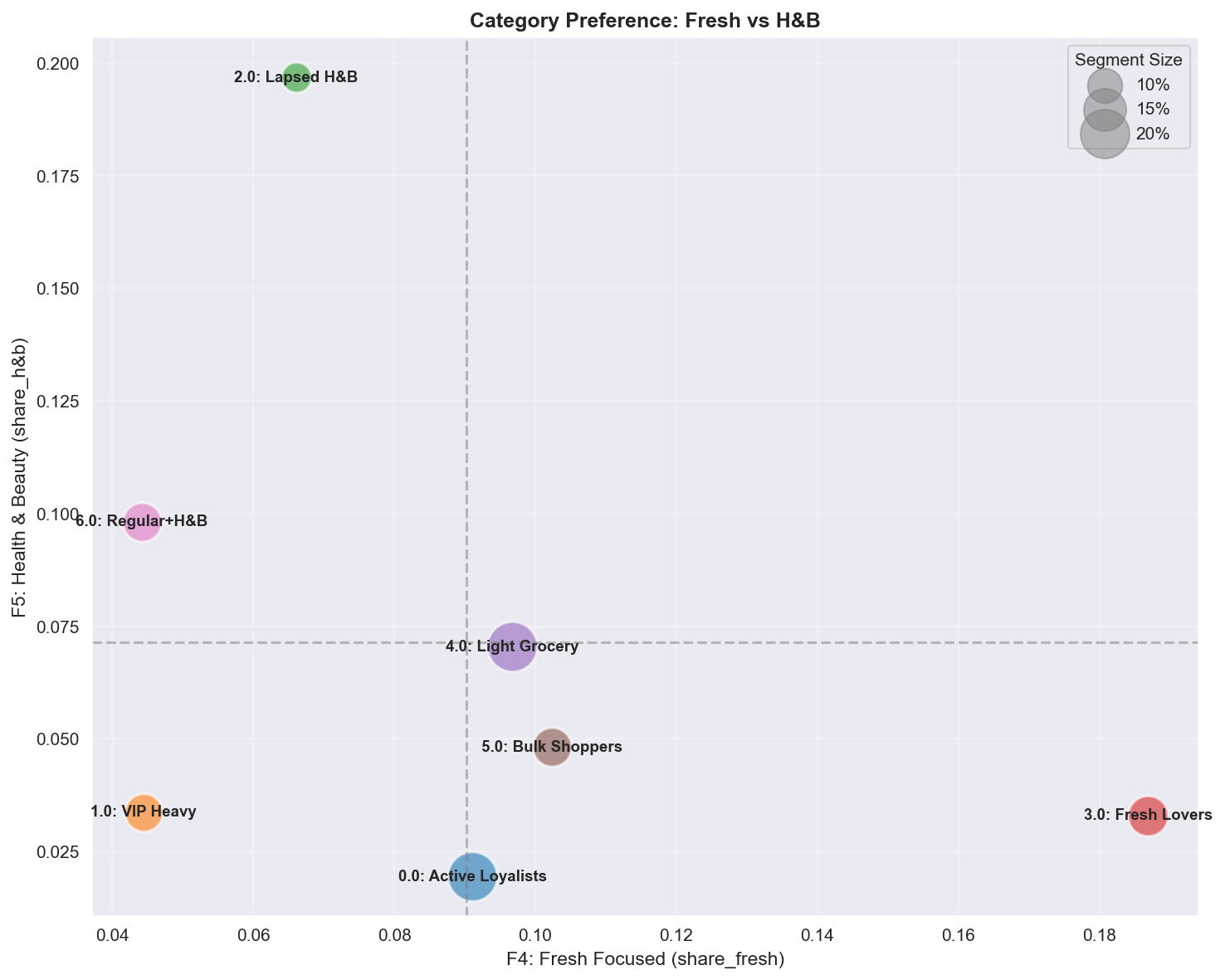
| Quadrant | Segments | Profile | Marketing action |
|---|---|---|---|
| High Fresh + Low H&B | Fresh Lovers | Cooking/health-focused | Recipe content, farm-to-store stories, daily fresh specials |
| Low Fresh + High H&B | Lapsed H&B, Regular+H&B | Drugstore needs | H&B sampling, beauty membership, health subscriptions |
| Balanced | VIP Heavy, Active Loyalists | Full-basket shoppers | Cross-category promotions, one-stop convenience |
| Low Both | Light Grocery, Bulk | Essentials-focused | Category-expansion incentives |
A.4.4 Frequency vs Monetary (RFM core)
| Quadrant | Segments | Profile | Marketing action |
|---|---|---|---|
| High Freq + High Monetary | VIP Heavy | Best customers | Protect at any cost, premium treatment |
| High Freq + Low Monetary | Active Loyalists | Frequent small spenders | Grow basket size, upselling |
| Low Freq + High Monetary | Bulk Shoppers | Warehouse-style | Increase visit frequency, subscriptions |
| Low Freq + Low Monetary | Lapsed, Light Grocery | At-risk/dormant | Segmentation to assess win-back ROI |
A.4.5 Regularity vs Average Basket Size
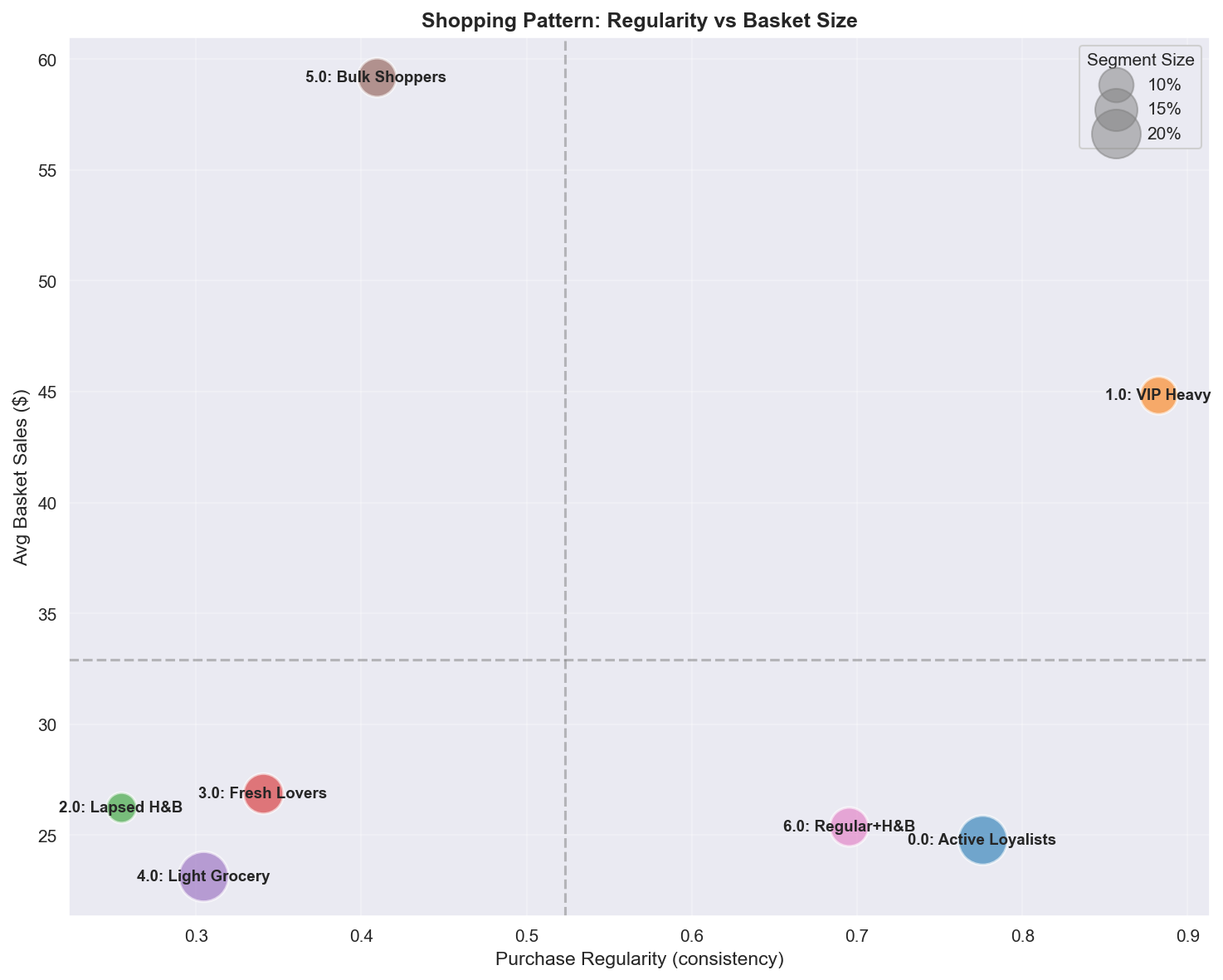
| Quadrant | Segments | Profile | Marketing action |
|---|---|---|---|
| High Regularity + High Basket | VIP Heavy | Predictable high-value | Maintain rhythm, anticipate needs |
| High Regularity + Low Basket | Active Loyalists | Consistent small visits | Shift from top-up to stock-up |
| Low Regularity + High Basket | Bulk Shoppers | Sporadic bulk shopping | Regularize via reminders and auto-replenishment |
| Low Regularity + Low Basket | Lapsed, Light | Unpredictable low-value | Accept or target reactivation |
A.4.6 Recency vs Monetary (lifecycle)
| Quadrant | Segments | Profile | Marketing action |
|---|---|---|---|
| Low Recency + High Monetary | VIP Heavy, Active Loyalists | Active high-value | Retention, prevent churn signals |
| Low Recency + Low Monetary | Fresh Lovers, Light Grocery | Active low-value | Grow value via cross-sell |
| High Recency + High Monetary | (rare) | Recently churned VIPs | Urgent win-back with premium offers |
| High Recency + Low Monetary | Lapsed H&B | Churned low-value | Low-priority win-back, accept churn |
A.4.7 Discount Rate vs Private Label Ratio
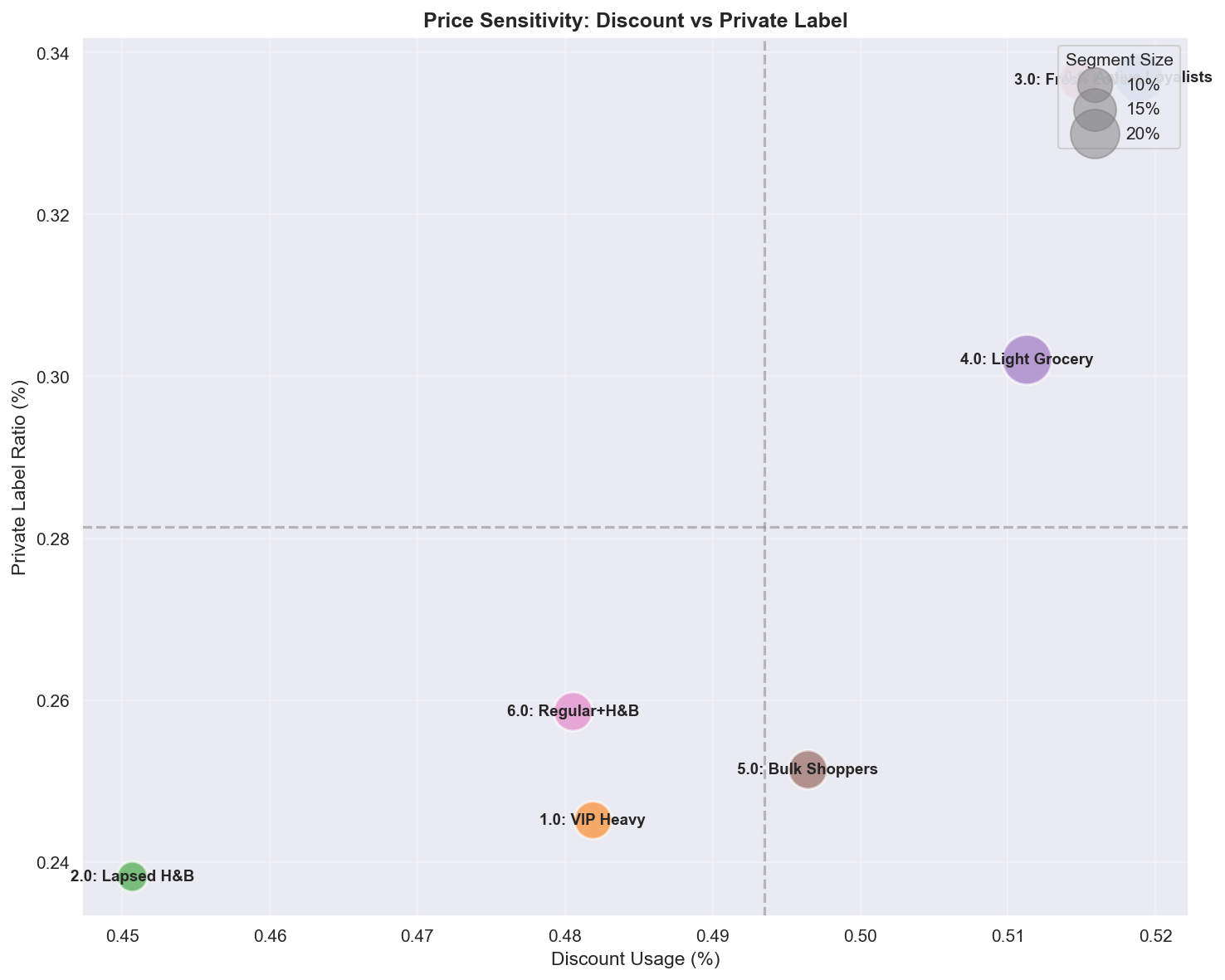
| Quadrant | Segments | Profile | Marketing action |
|---|---|---|---|
| High Discount + High PL | Active Loyalists | Budget maximizers | PB-centric promotions, value messaging |
| High Discount + Low PL | Fresh Lovers | Brand-loyal discount seekers | NB promotions, PB trial incentives |
| Low Discount + High PL | Regular+H&B | Quality-seeking PB fans | Premium PB lines, new PB launches |
| Low Discount + Low PL | VIP Heavy, Bulk | Price-indifferent | Avoid discounts, focus on convenience/quality |
A.4.8 Shopping Variety vs Regularity
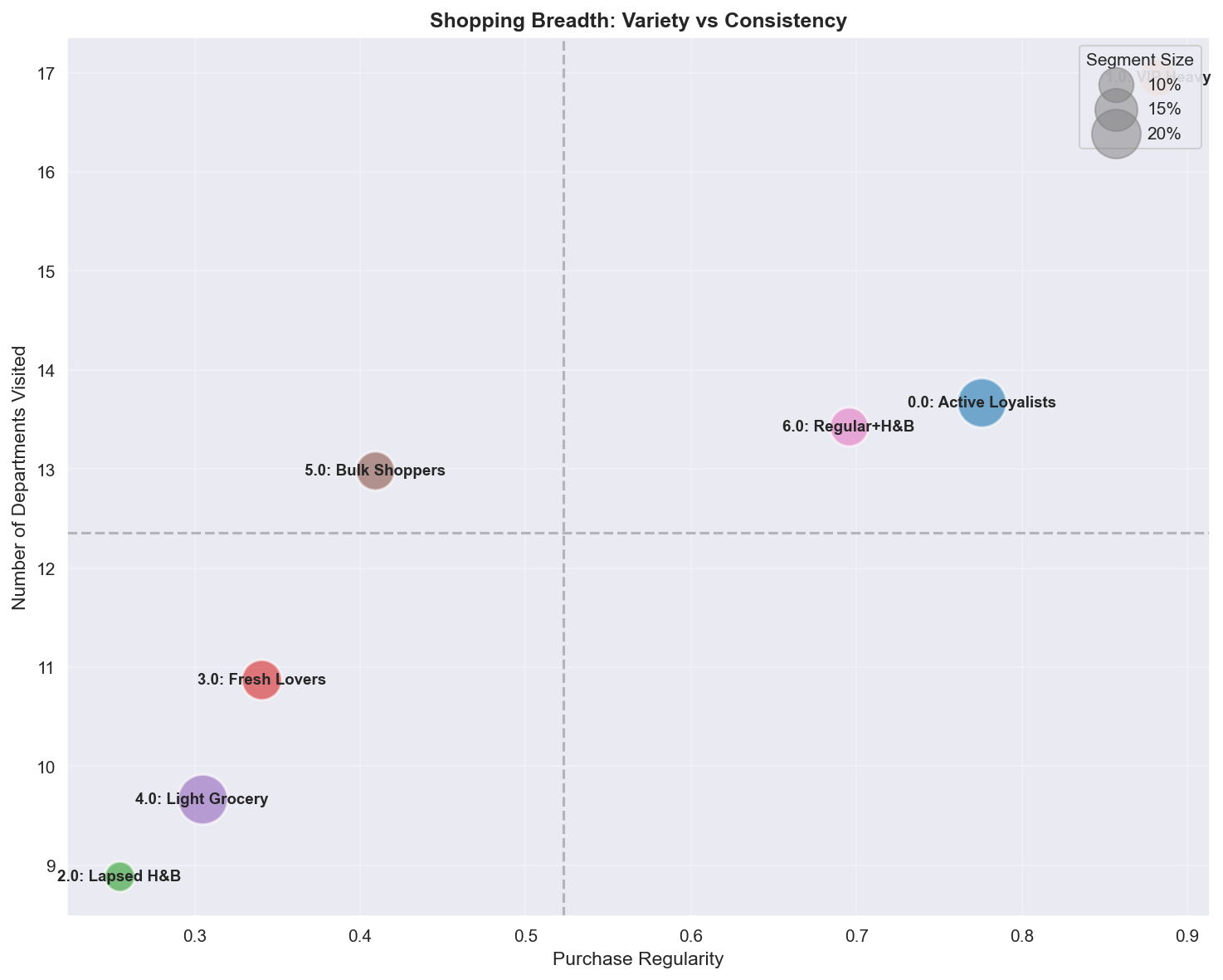
| Quadrant | Segments | Profile | Marketing action |
|---|---|---|---|
| High Variety + High Regularity | VIP Heavy | Ultimate one-stop shoppers | Full personalization, category captain |
| High Variety + Low Regularity | Bulk Shoppers | Occasional comprehensive shopping | Convert to a regular cadence |
| Low Variety + High Regularity | Fresh Lovers | Category specialists | Category deepening, adjacent expansion |
| Low Variety + Low Regularity | Lapsed, Light | Narrow, irregular | Expand basket first, then frequency |
A.5 Clustering Evaluation Metrics Full Table (clustering_metrics.csv)
The full internal validation metrics for the candidate k values. Note that DBI is minimized at k=7 (1.241), while Silhouette is maximized at lower k (k=3 = 0.271).
| k | Silhouette | Calinski-Harabasz | Davies-Bouldin | Note |
|---|---|---|---|---|
| 3 | 0.271 | 984.9 | 1.256 | Silhouette max |
| 5 | 0.225 | 794.2 | 1.321 | |
| 6 | 0.207 | 756.3 | 1.342 | DBI worst |
| 7 | 0.219 | 732.0 | 1.241 | Selected (DBI min + interpretability + stability) |
| 8 | 0.209 | 700.2 | 1.244 |
Interpretation note: Looking at a single metric only, Silhouette prefers lower k and Calinski-Harabasz prefers the lowest k. However, since (1) the DBI minimum is achieved at k=7, (2) the 7 segments have the actionability of mapping 1:1 to marketing actions, and (3) they are robust with Bootstrap ARI 0.77 ± 0.11, we adopted k=7. We record the disagreement among the metrics honestly rather than hiding it.
References
Segmentation Methods
- Lee, D. D., & Seung, H. S. (1999). Learning the parts of objects by non-negative matrix factorization. Nature, 401(6755), 788-791.
- Wedel, M., & Kamakura, W. A. (2000). Market Segmentation: Conceptual and Methodological Foundations. Springer.
- Punj, G., & Stewart, D. W. (1983). Cluster analysis in marketing research: Review and suggestions for application. Journal of Marketing Research, 20(2), 134-148.
Retail Marketing
- Rossi, P. E., McCulloch, R. E., & Allenby, G. M. (1996). The value of purchase history data in target marketing. Marketing Science, 15(4), 321-340.
- Hughes, A. M. (1994). Strategic Database Marketing. Probus Publishing.
Clustering Validation
- Rousseeuw, P. J. (1987). Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. Journal of Computational and Applied Mathematics, 20, 53-65.
- Hubert, L., & Arabie, P. (1985). Comparing partitions. Journal of Classification, 2(1), 193-218.